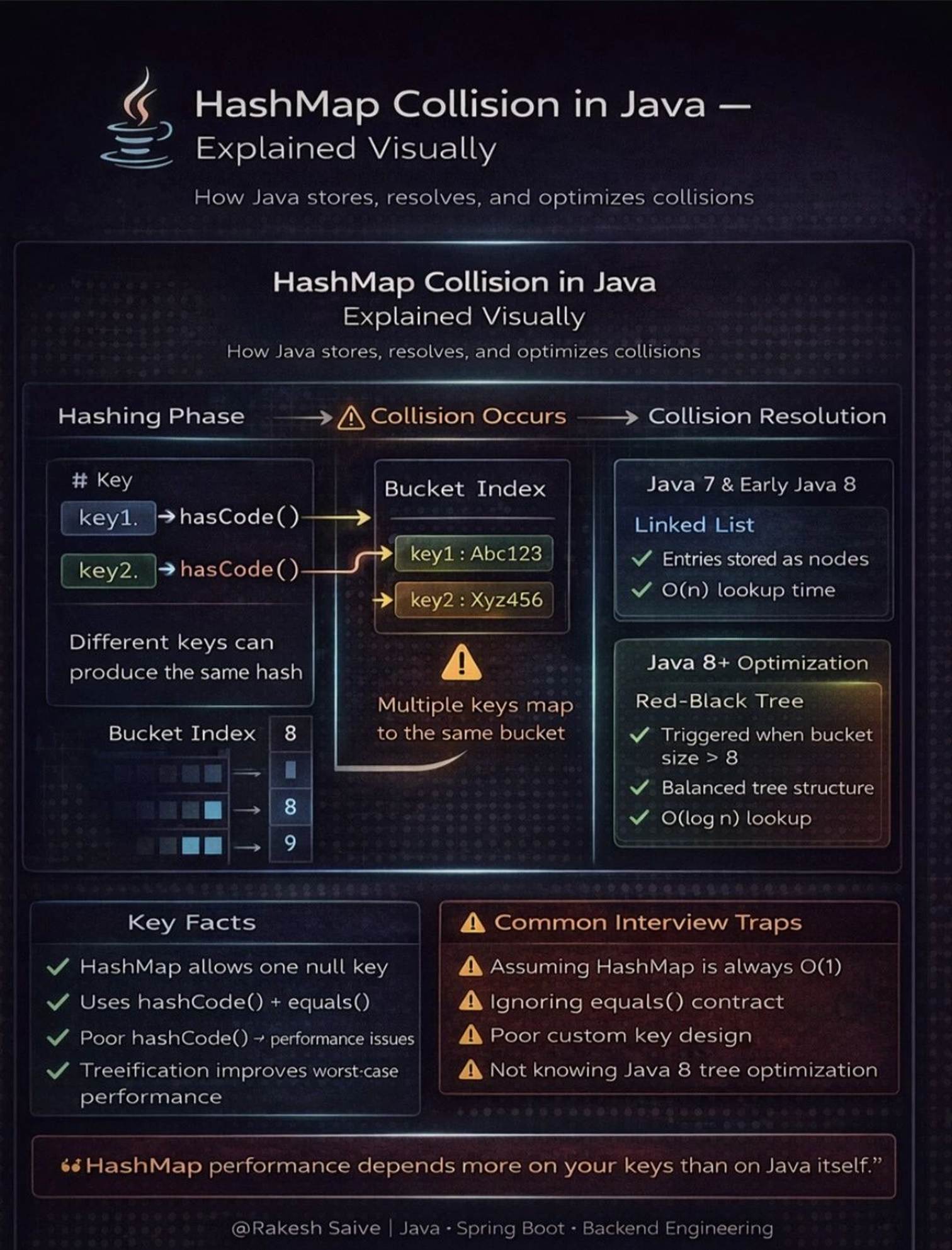
Hashing:
· HashMap uses a hash function to compute an index (hash code) into an array of buckets or slots from which the desired value can be found.
· Node Structure:
· Each Node (or Entry in earlier versions) contains a key, a value, the hash code, and a reference to the next node in the list (for collision resolution).
· Put Operation:
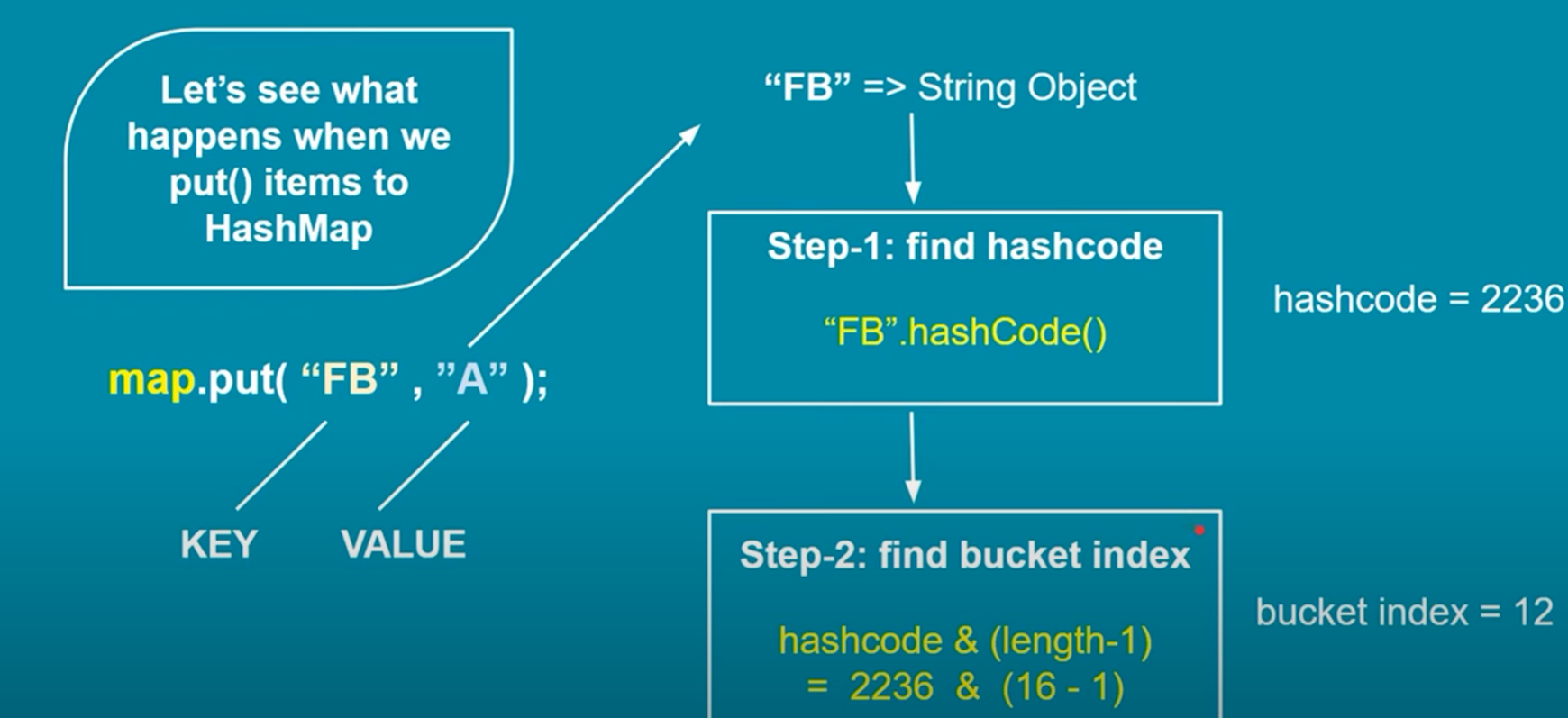
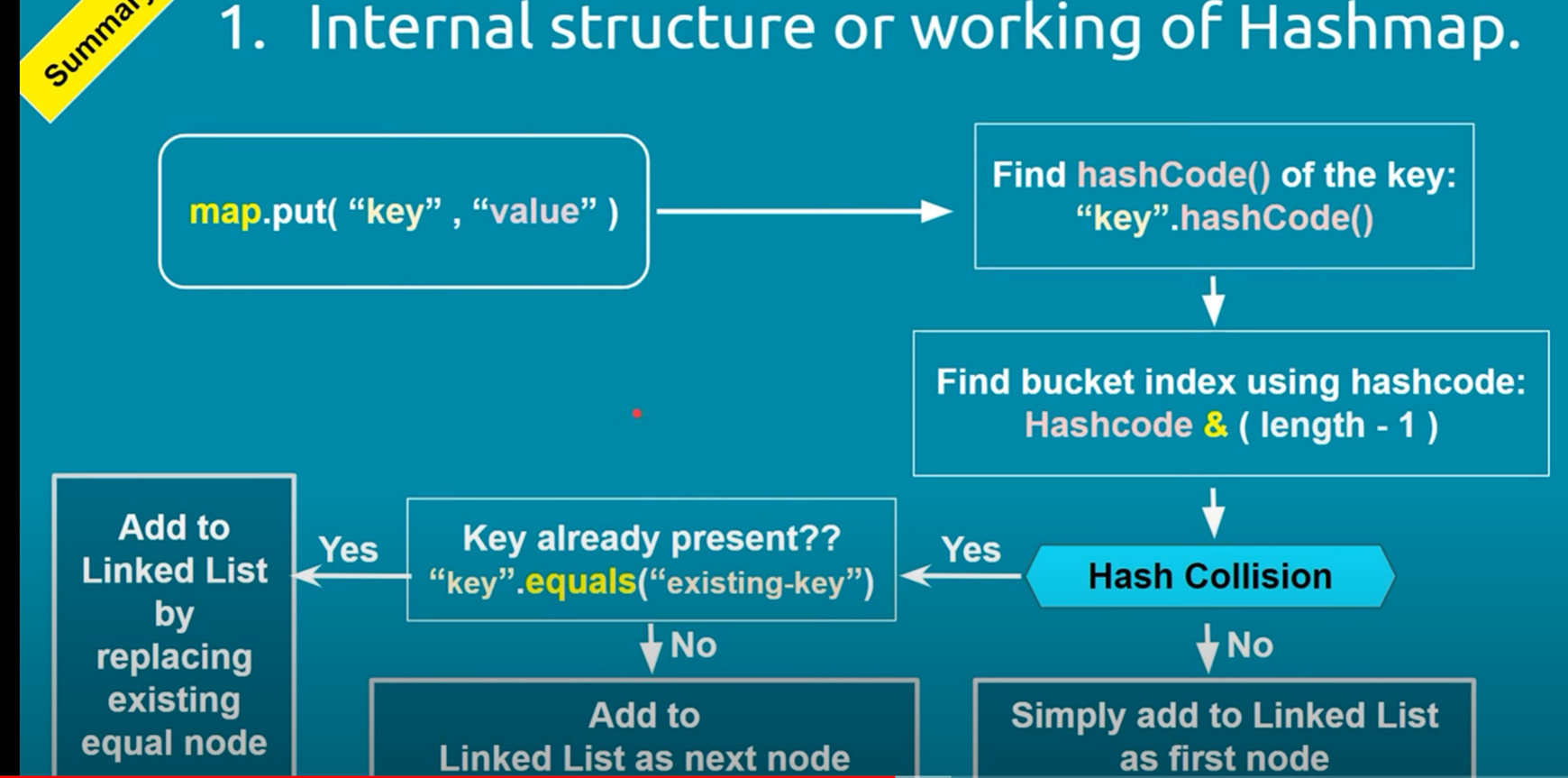
· The put() method adds a key-value pair to the HashMap.
· The key's hash code is computed, and the corresponding bucket index is determined.
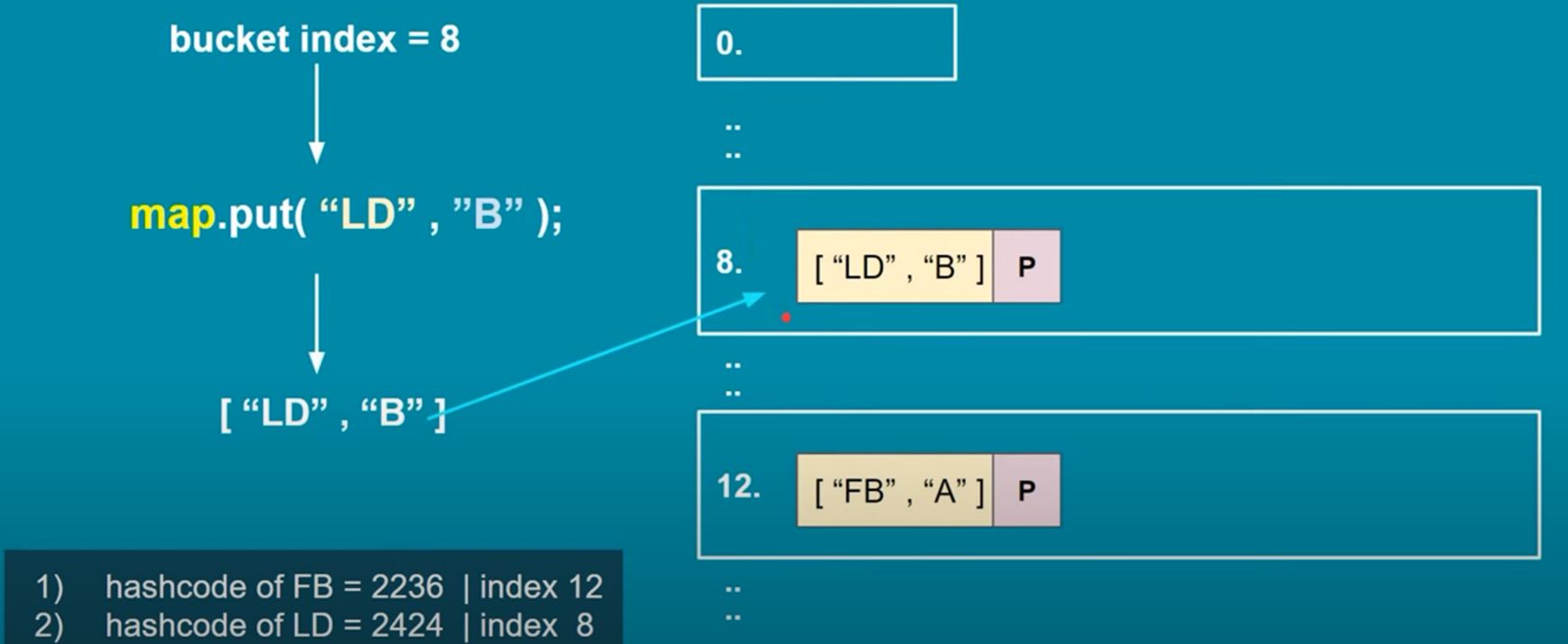
· If the bucket is empty, the entry is added directly.
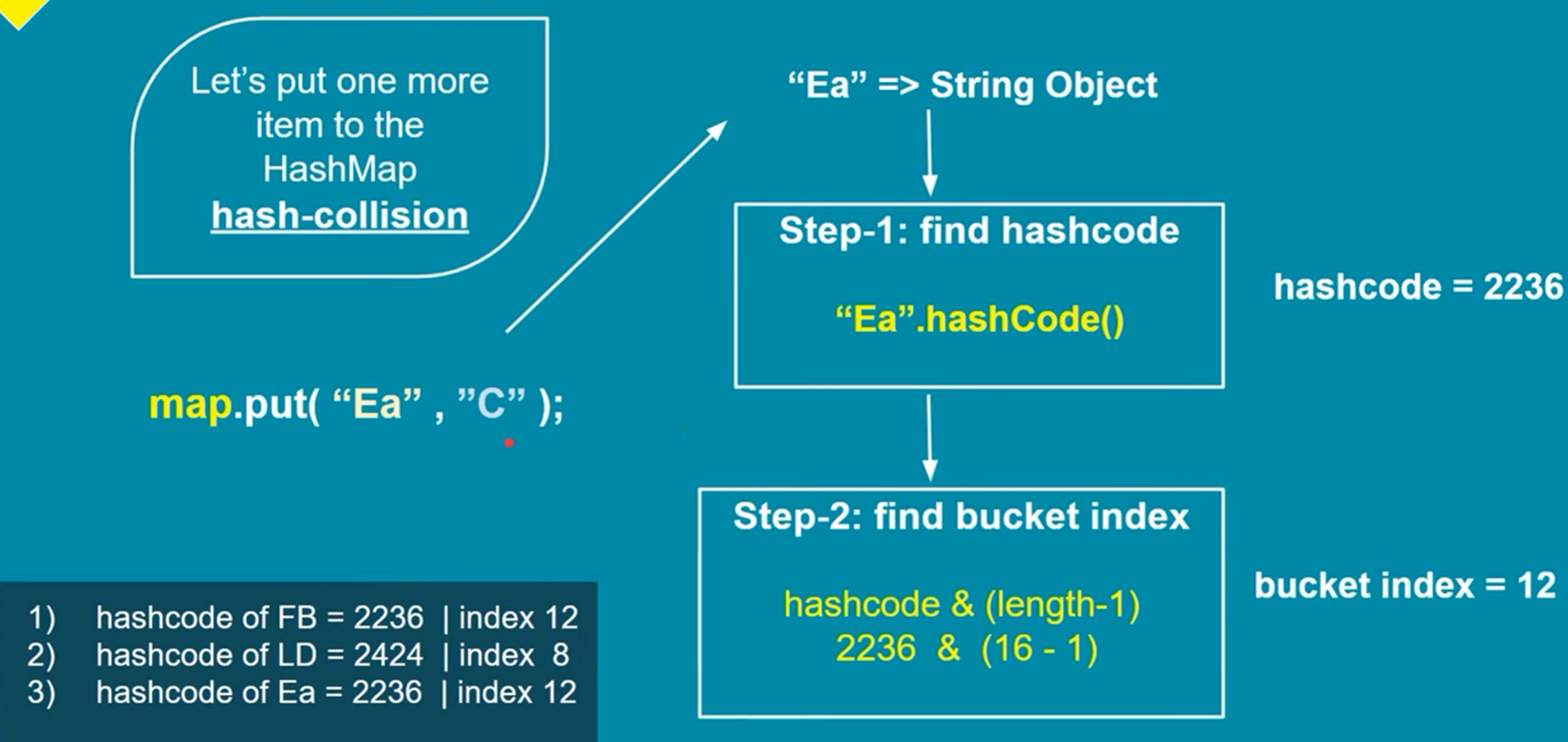
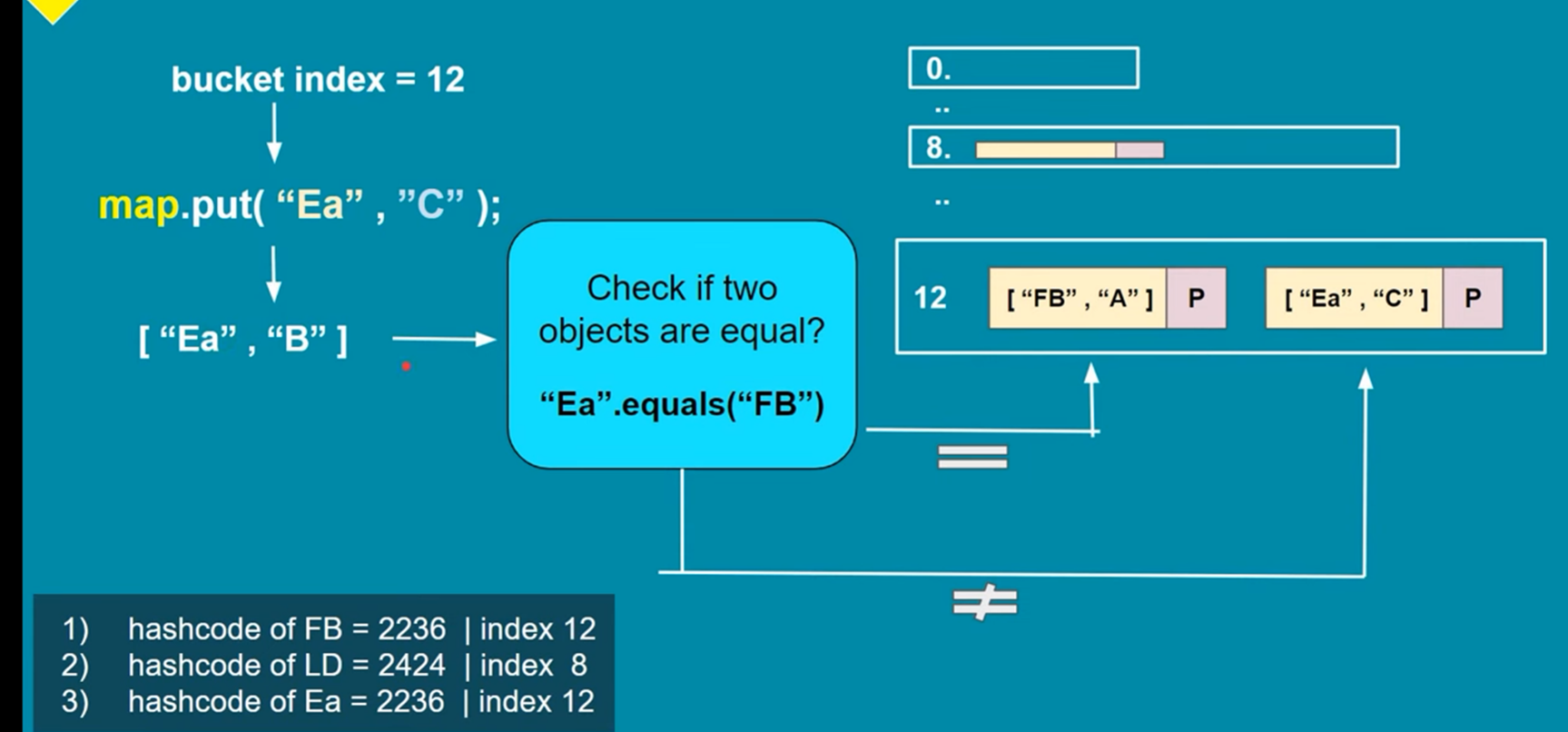
· If the bucket contains entries, the map checks if the key already exists and updates the value if it does. Otherwise, the new entry is added to the list or tree within the bucket.
· Get Operation:
· The get() method retrieves the value for a given key.
· The key's hash code is computed, and the corresponding bucket index is determined.
· The map traverses the list or tree in the bucket, comparing the keys using the equals() method, and returns the value if the key is found.
1. Hash Function: When a key-value pair is added to the HashMap, a hash function (typically the hashCode() method) is applied to the key to generate a hash code. This hash code is an integer representation of the key. The hashCode() method can be overridden to provide a custom implementation.
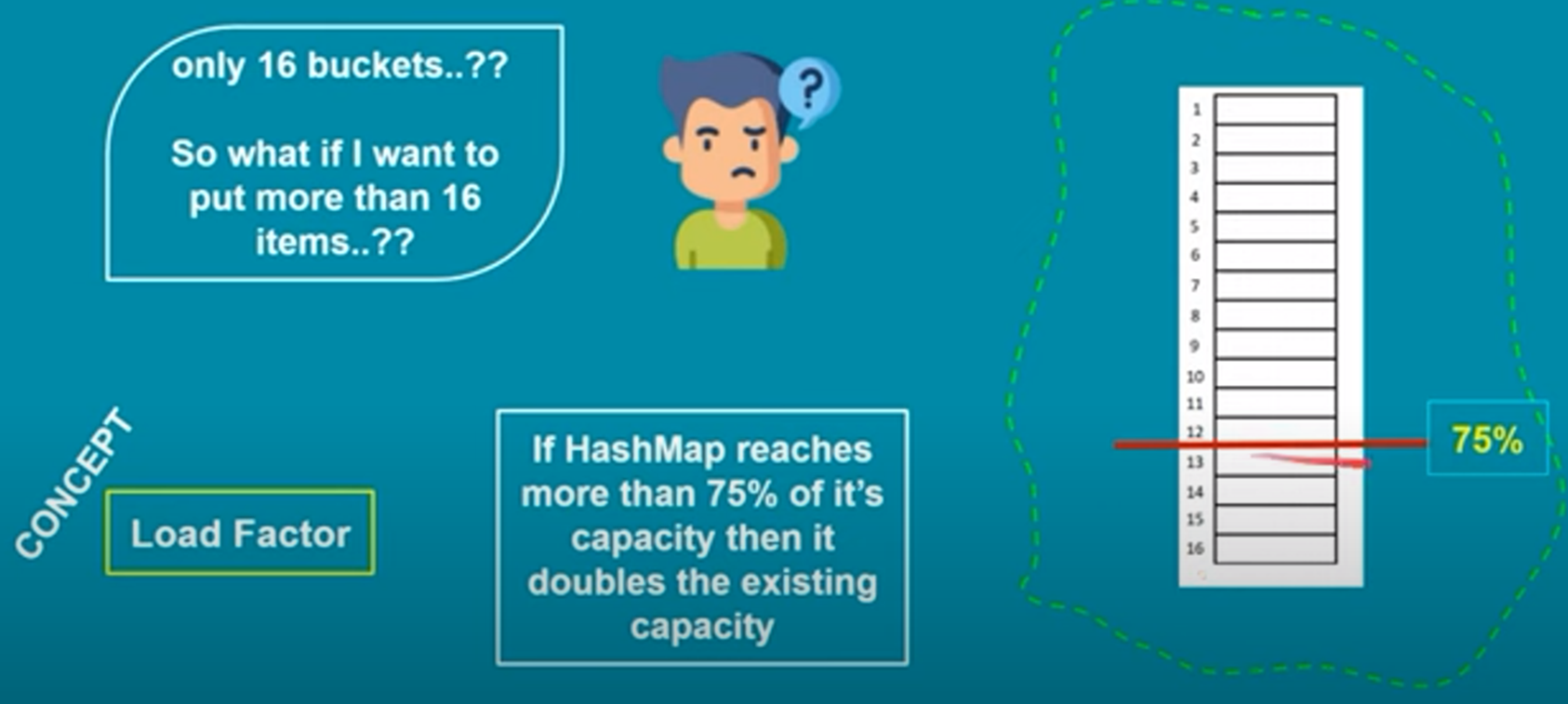
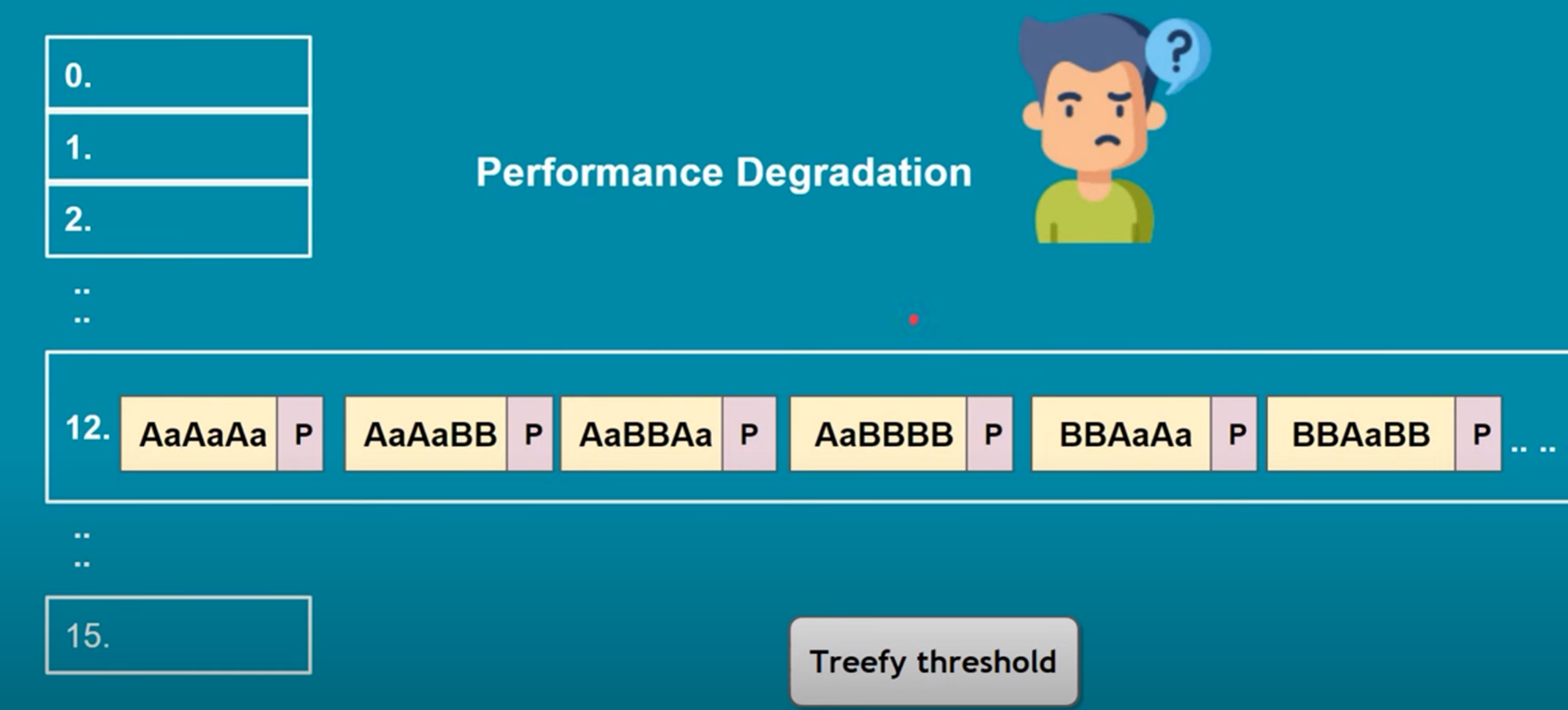
2. Hash Code and Buckets: The generated hash code is used to determine the bucket or index in the internal array (also known as a "bucket array") where the key-value pair will be stored. The size of this array depends on the initial capacity of the HashMap, which defaults to 16. Multiple keys may produce the same hash code, resulting in a collision.
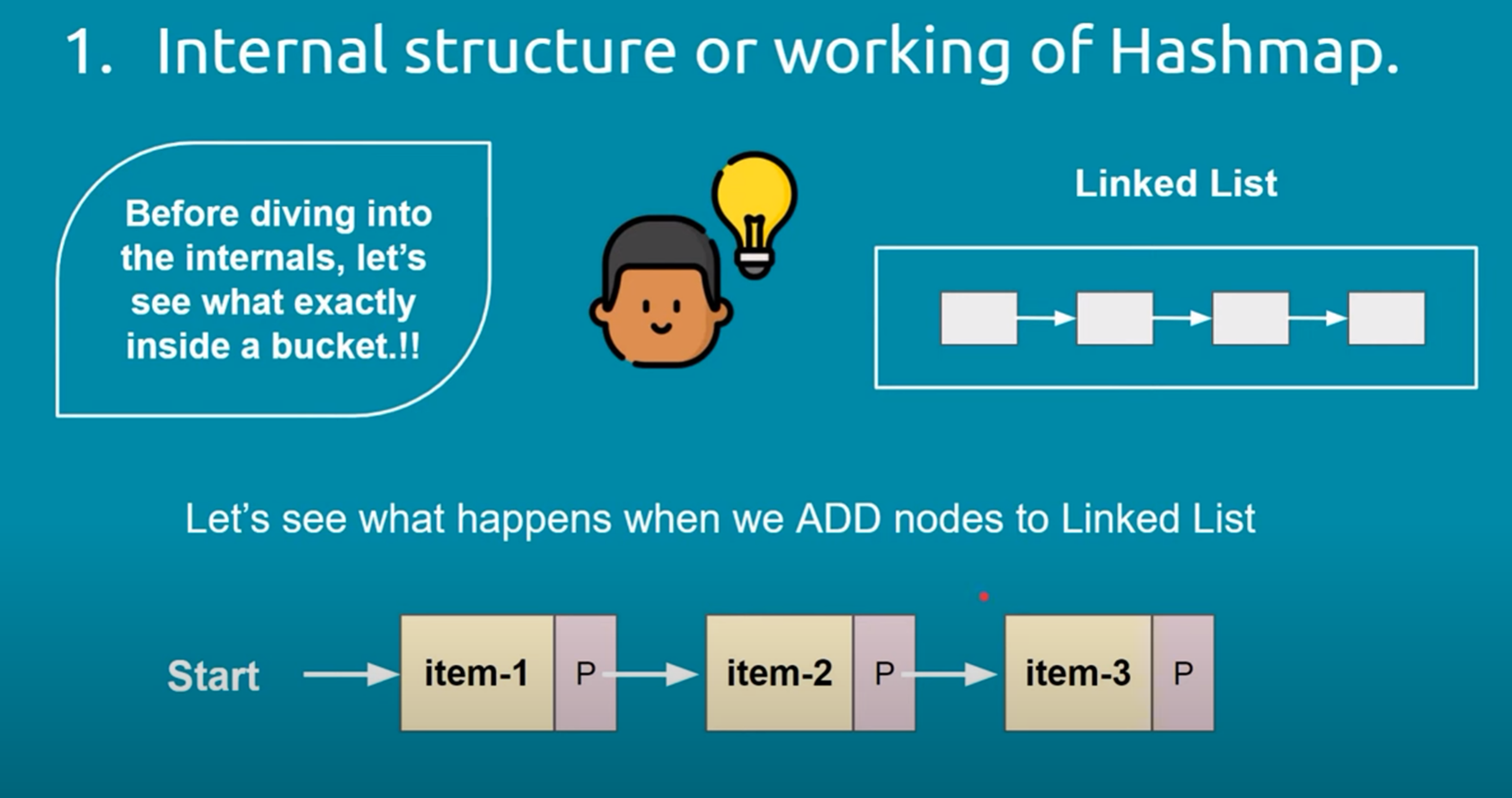
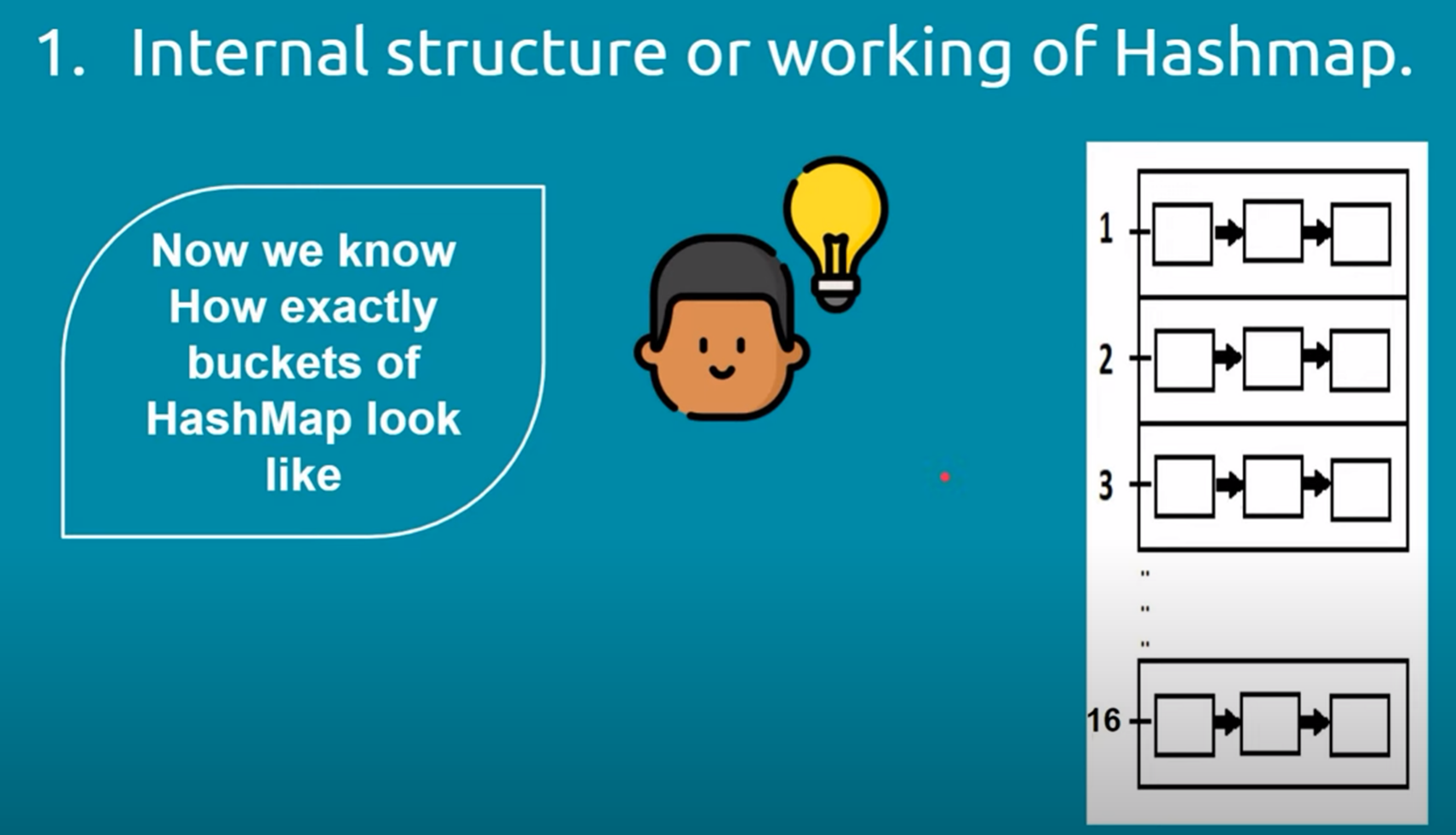
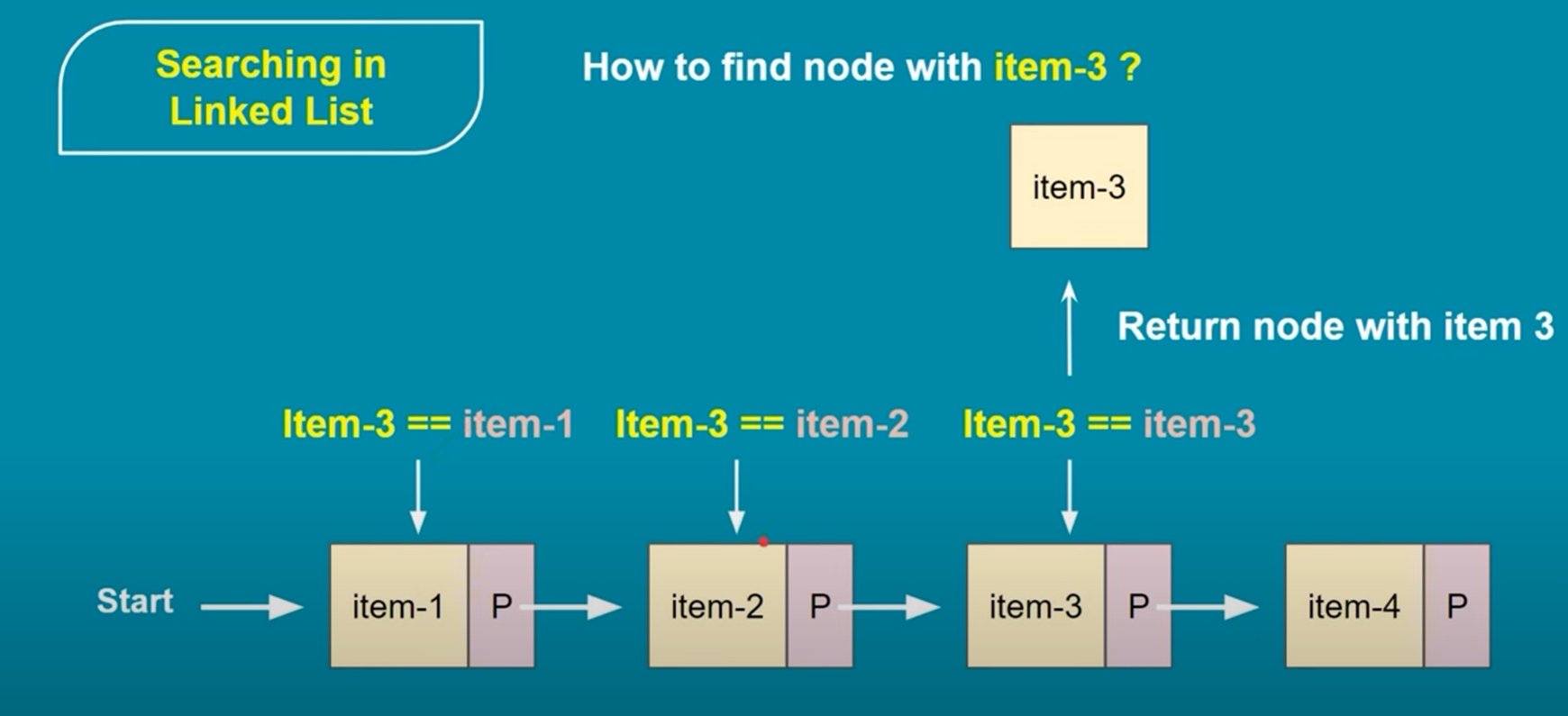
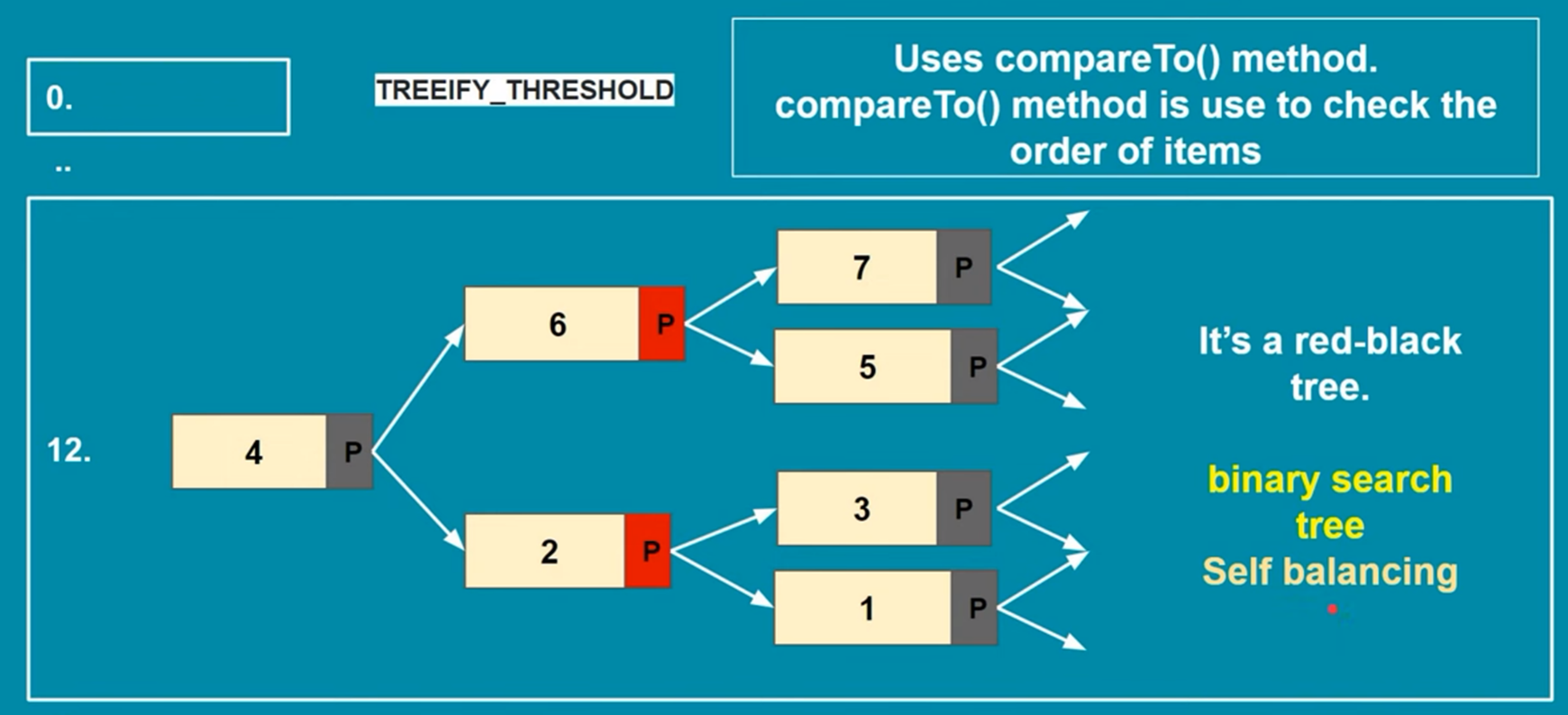
3. Collision Handling: To handle collisions, the HashMap uses separate chaining with linked lists (specifically, a variant of a singly linked list). This means that if two keys produce the same hash code, they will be stored in the same bucket, but as part of a linked list. Each bucket can hold multiple key-value pairs if collisions occur.
4. Retrieval: When retrieving a value based on a key, the hash code of the key is calculated, and the corresponding bucket is located in the array. If there are multiple key-value pairs in that bucket (due to collisions), the equals() method is used to compare the keys and find the correct value.
5. Duplicate Keys: HashMap does not allow duplicate keys. If a value is associated with a key that already exists in the HashMap, the new value will replace the old one.
6. Internal Data Structure: The HashMap uses an array of Nodes to store the key-value pairs. Each Node contains the hash code, the key, the value, and a reference to the next Node in the linked list (in case of collisions).

public class Employee {
private int id;
private String name;
public Employee(int id, String name) {
this.id = id;
this.name = name;
}
// Override equals() and hashCode() methods
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return id == employee.id &&
Objects.equals(name, employee.name);
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
@Override
public String toString() {
return "Employee{id=" + id + ",
name='" + name + "'}";
}
}
class Main {
public static void main(String[] args) {
HashMap<Employee, String> employeeMap = new HashMap<>();
Employee emp1 = new Employee(1, "John");
Employee emp2 = new Employee(2, "Jane");
employeeMap.put(emp1, "HR");
employeeMap.put(emp2, "Engineering");
System.out.println(employeeMap.get(emp1)); //
Output: HR
System.out.println(employeeMap.get(emp2)); //
Output: Engineering
}
}