Iterator can traverse in forward direction only whereas ListIterator can be used to traverse in both the directions.
ListIterator inherits from Iterator interface and comes with extra functionalities like adding an element, replacing an element, getting index position for previous and next elements.
List<String> strList = new ArrayList<>();
//using for-each loop
for(String obj : strList){
System.out.println(obj);
}
//using iterator
Iterator<String> it = strList.iterator();
while(it.hasNext()){
String obj = it.next();
System.out.println(obj);
}
http://www.javamadesoeasy.com/2015/01/single-linkedlist-insertdelete-at-first.html
Stack
Adding item in Stack is called PUSH.
Removing item from stack is called POP.
Push and pop operations happen at Top of stack.
Stack follows LIFO (Last in first out) - means last added element is removed first from stack.

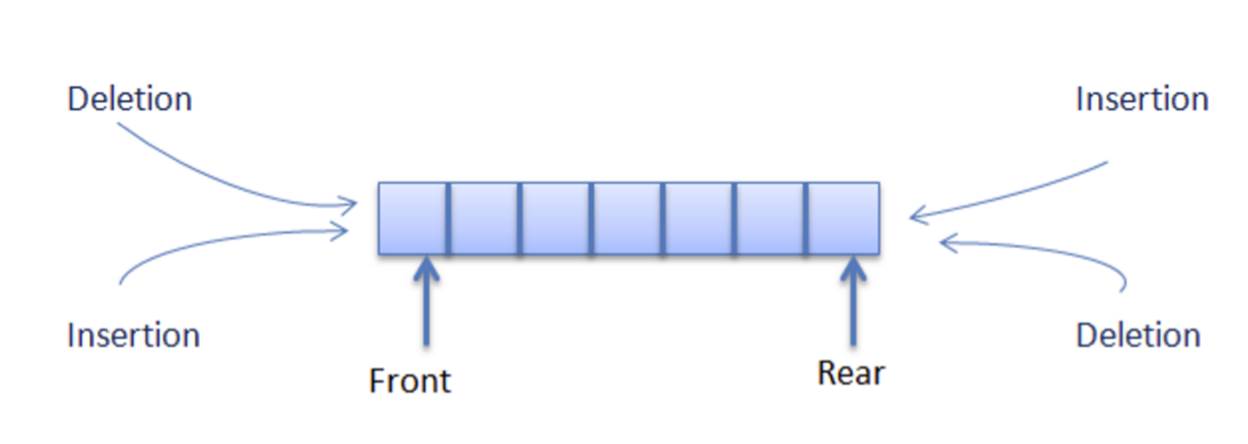
Queue
Addition of element is done at REAR.
Removal of element is done at FRONT.
Queue follows FIFO (First in first out) - means the first element added to the queue will be the first one to be removed.

 |
 |
· Vectors are synchronized, ArrayLists are not.
List list = Collections.synchronizedList(new ArrayList());
... //If you wanna use iterator on the synchronized list, use it//like this. It should be in synchronized block.synchronized (list) {
Iterator iterator = list.iterator();
while (iterator.hasNext())
...
iterator.next();
...
}
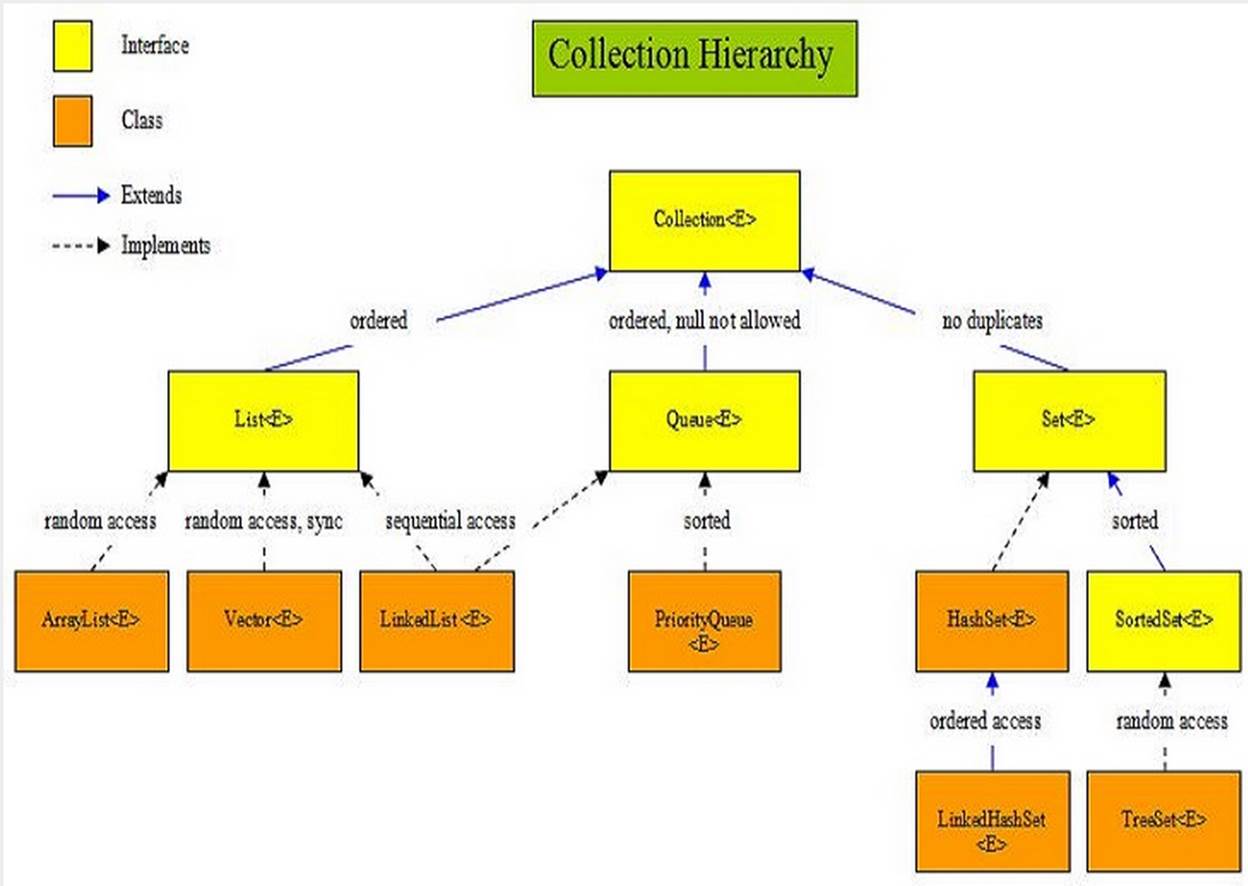
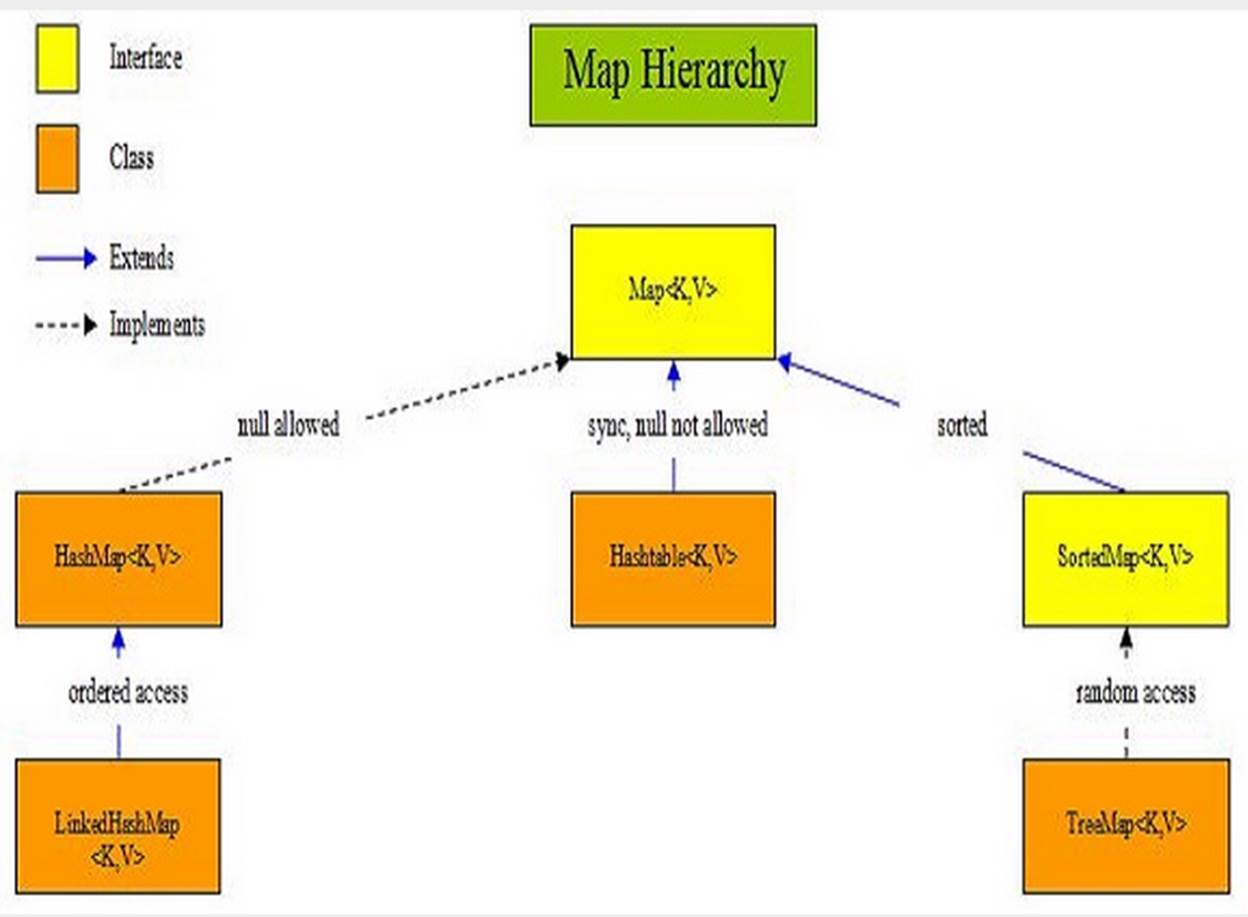
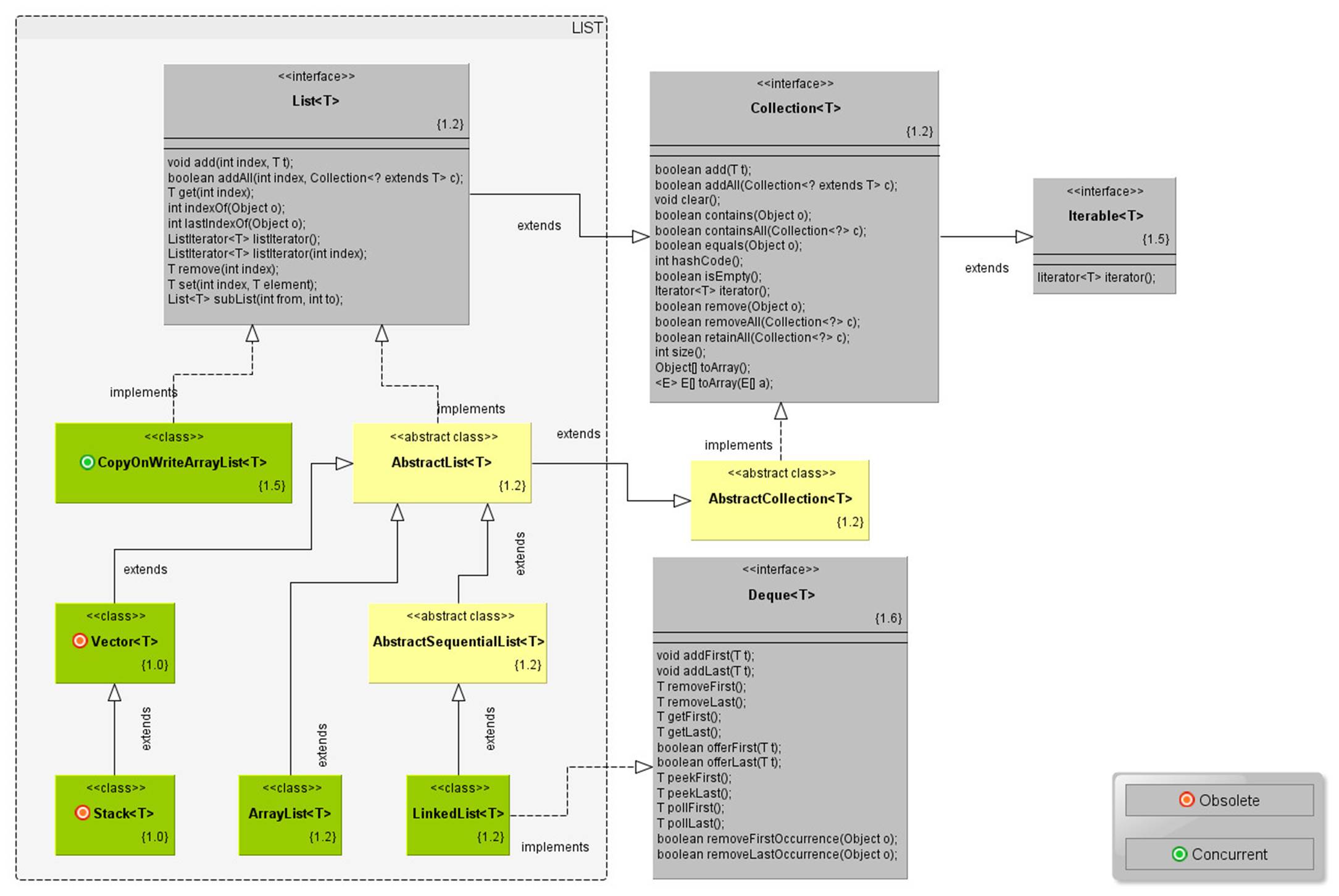
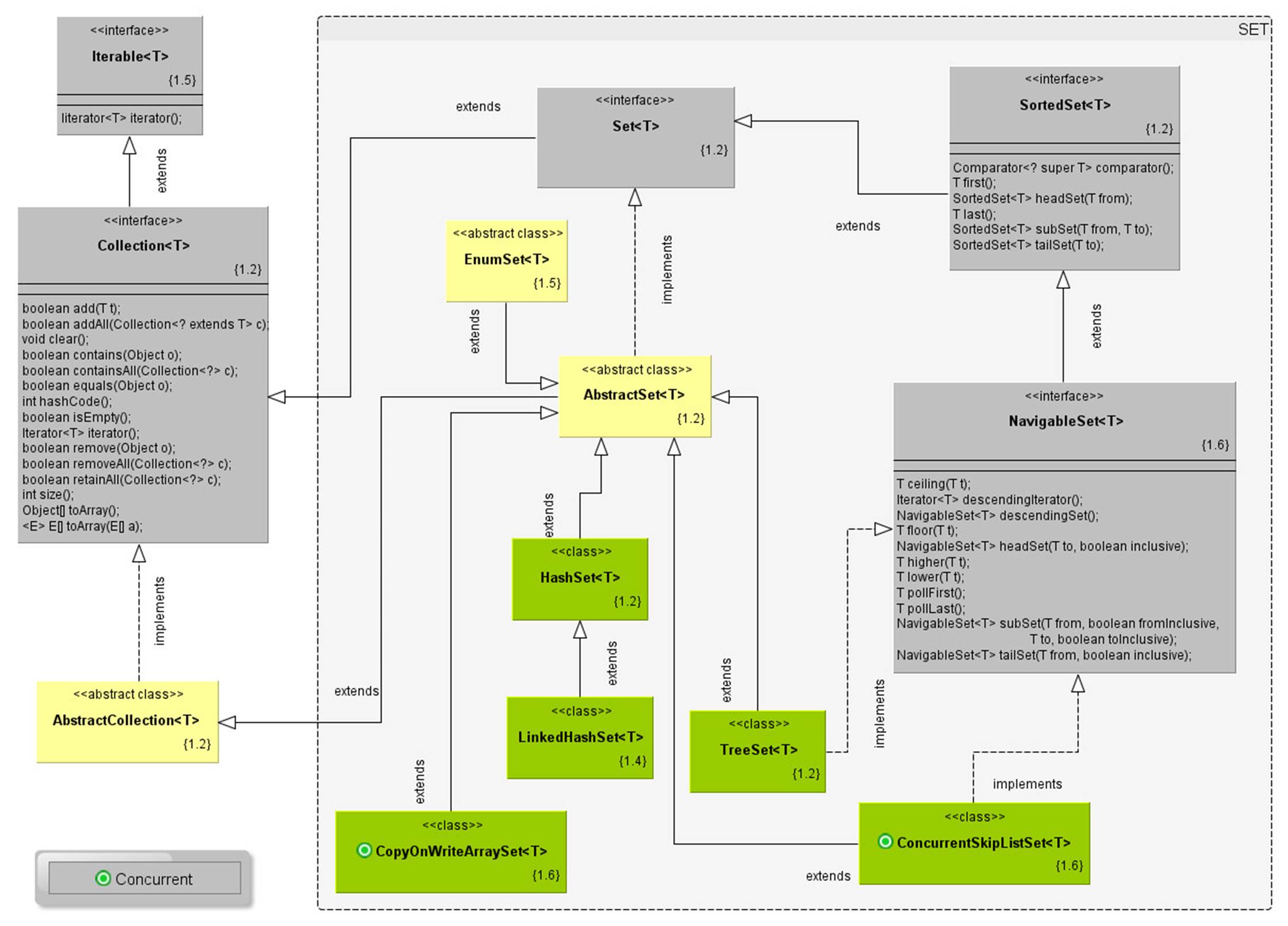
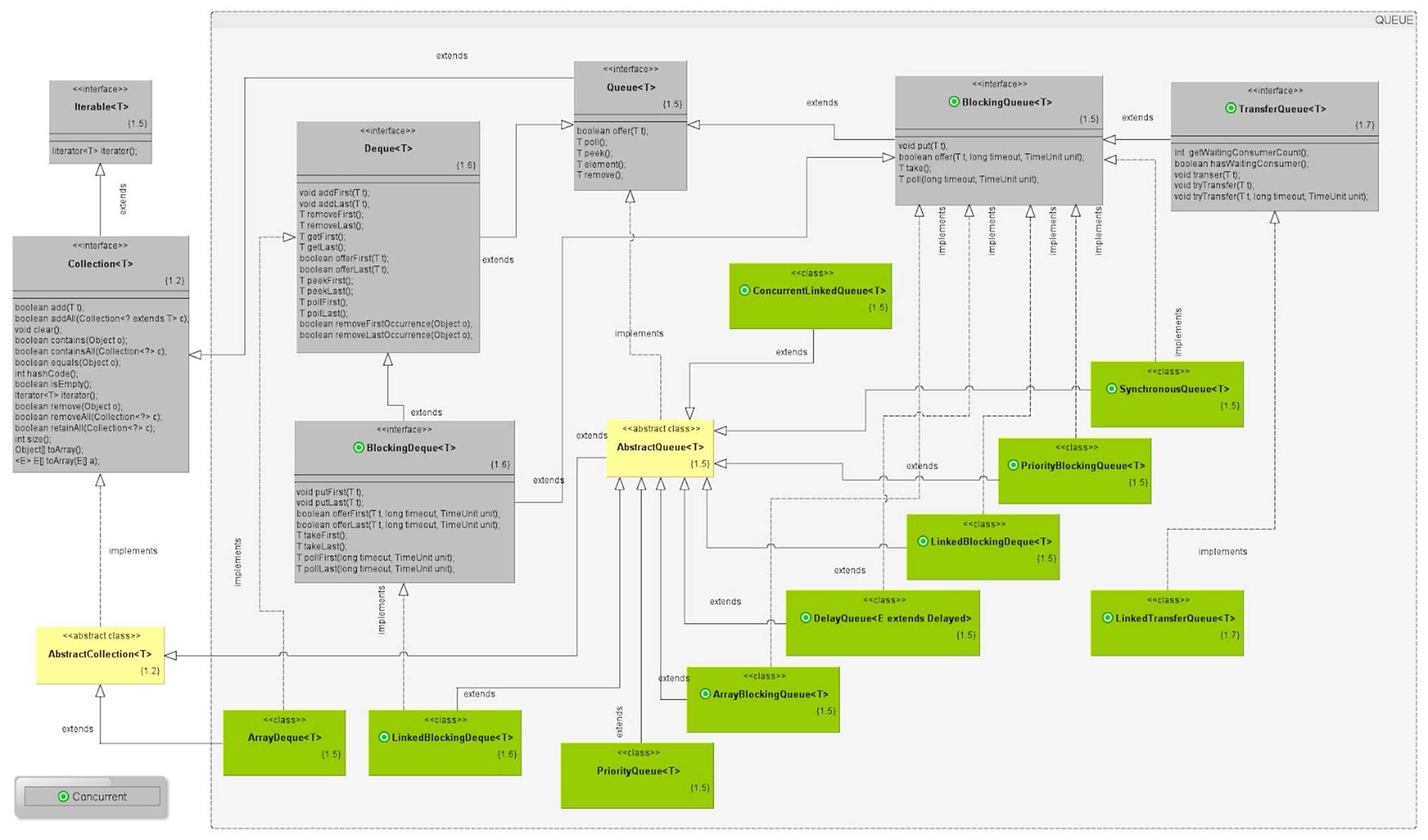
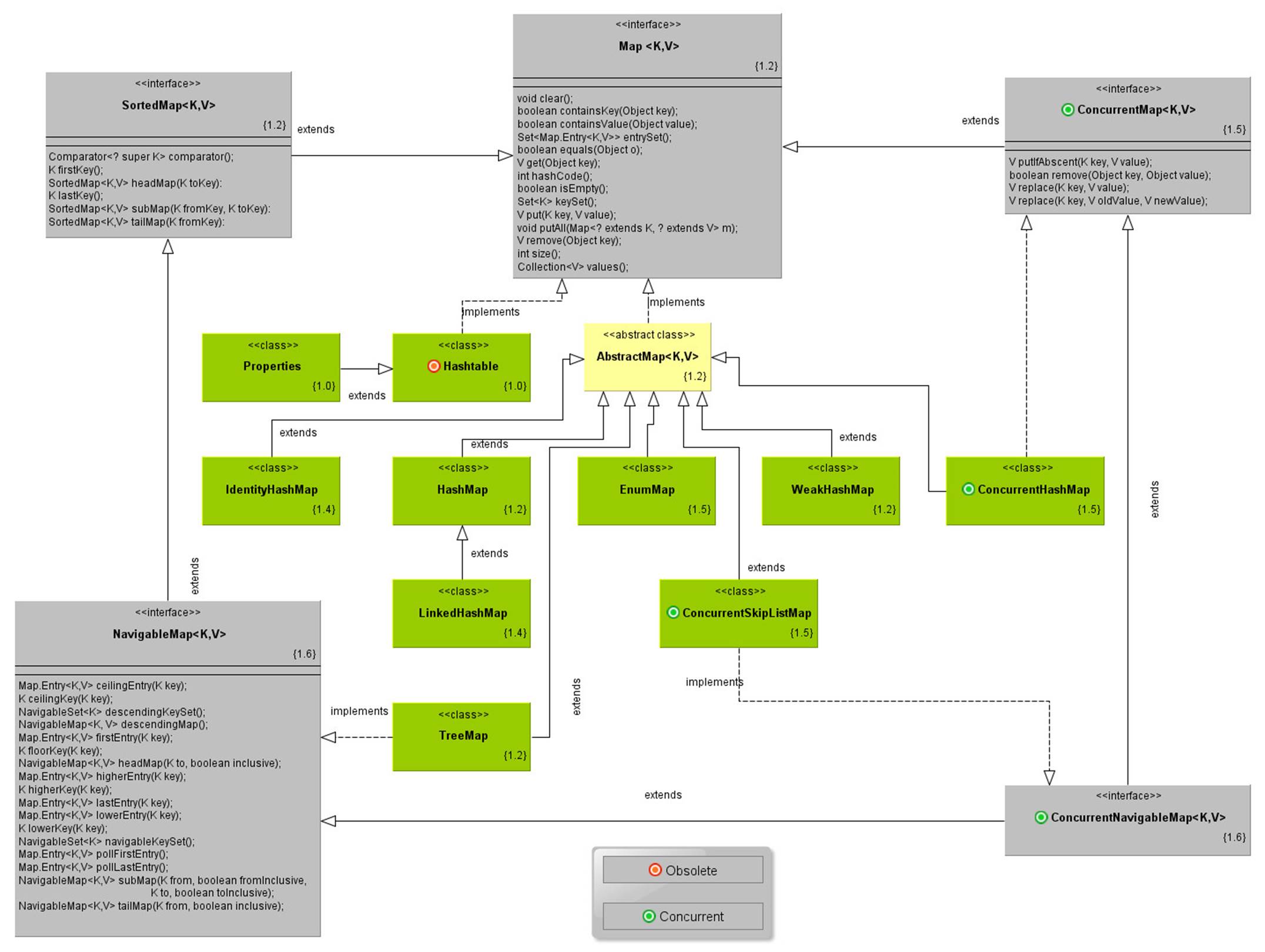
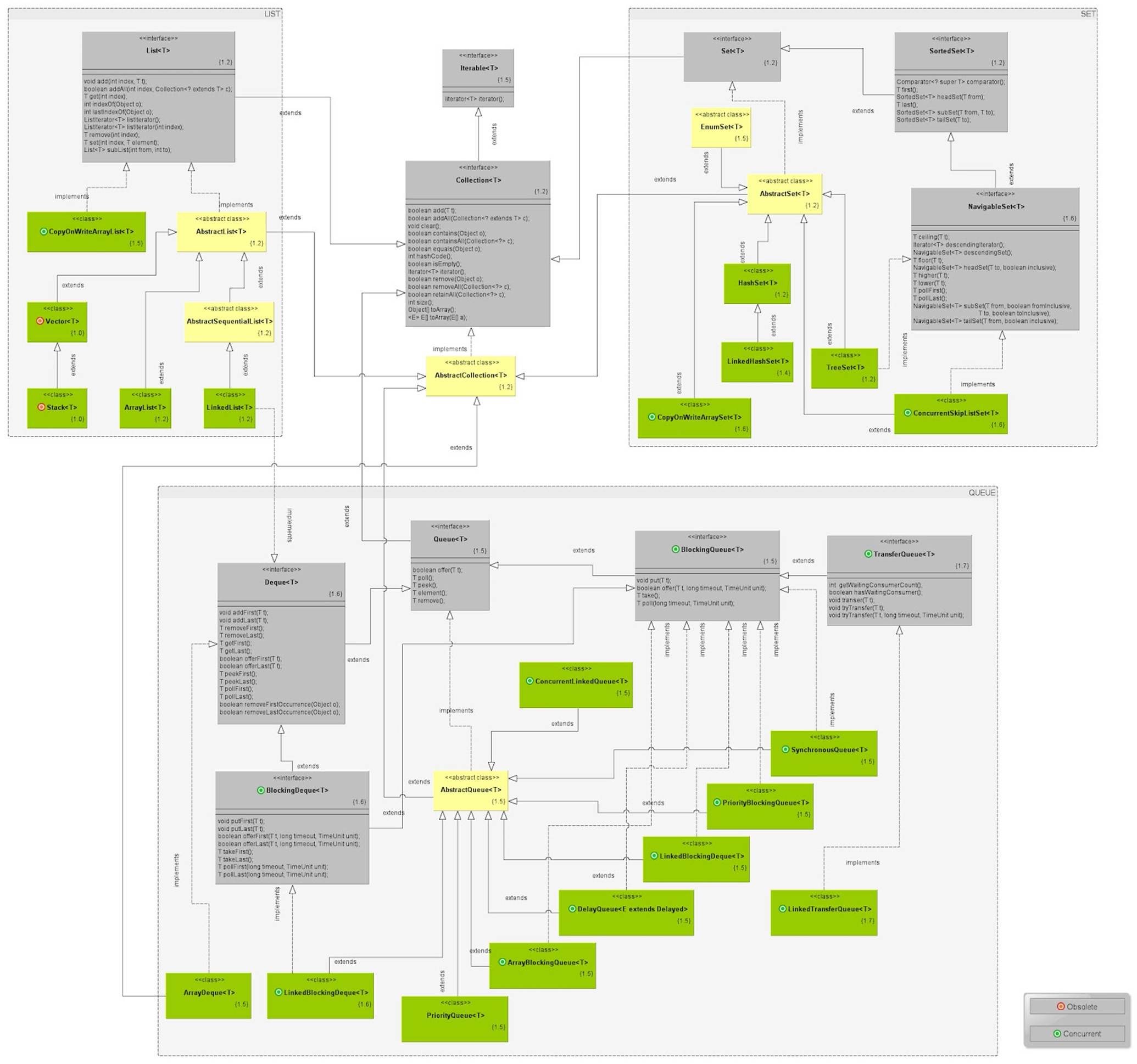
http://www.falkhausen.de/en/diagram/html/java.util.Collection.html
http://www.karambelkar.info/2012/06/java-collections-uml-class-diagrams.html
 |
 |
 |
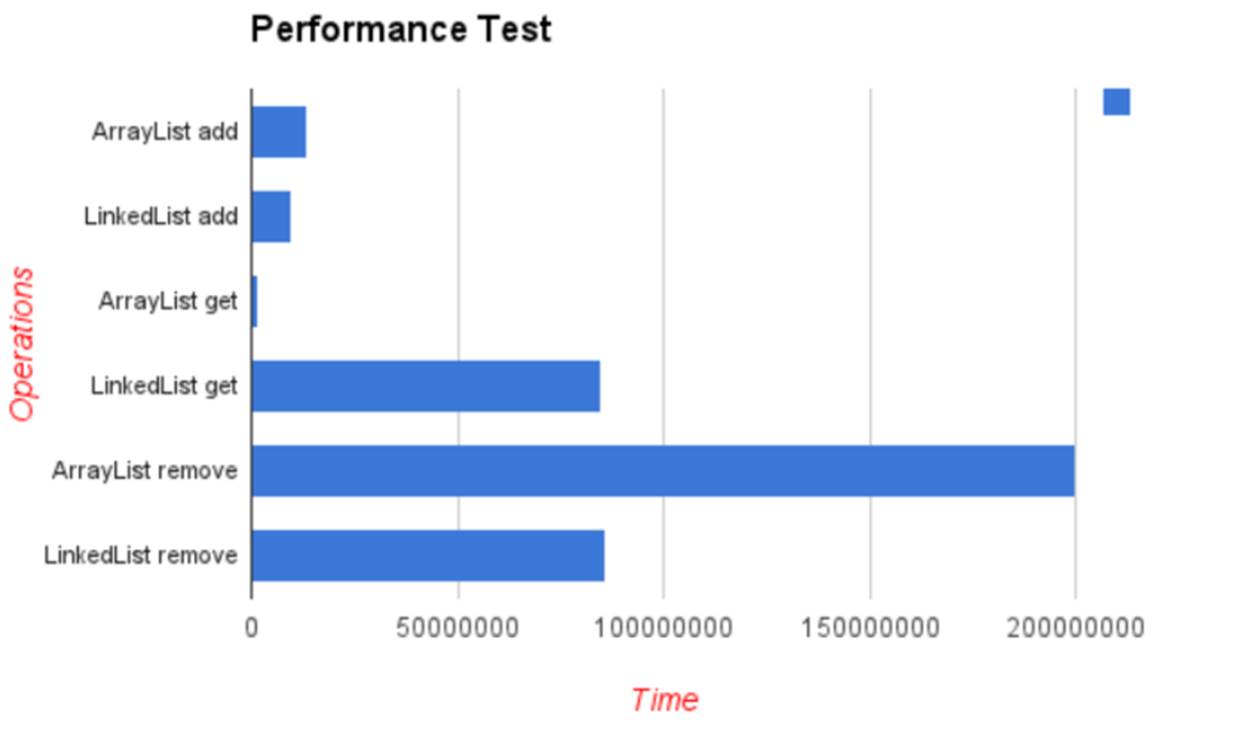 |
· LinkedList is faster in add and remove, but slower in get. Based on the complexity table and testing results, we can figure out when to use ArrayList or LinkedList. In brief, LinkedList should be preferred if:
· there are no large number of random access of element
· there are a large number of add/remove operations
·
· ArrayList is implemented as a resizable array. As more elements are added to ArrayList, its size is increased dynamically. It's elements can be accessed directly by using the get and set methods, since ArrayList is essentially an array.
· LinkedList is implemented as a double linked list. Its performance on add and remove is better than Arraylist, but worse on get and set methods.
· Vector is similar with ArrayList, but it is synchronized.
· Vector each time doubles its array size, while ArrayList grow 50% of its size each time. LinkedList, however, also implements Queue interface
·
·
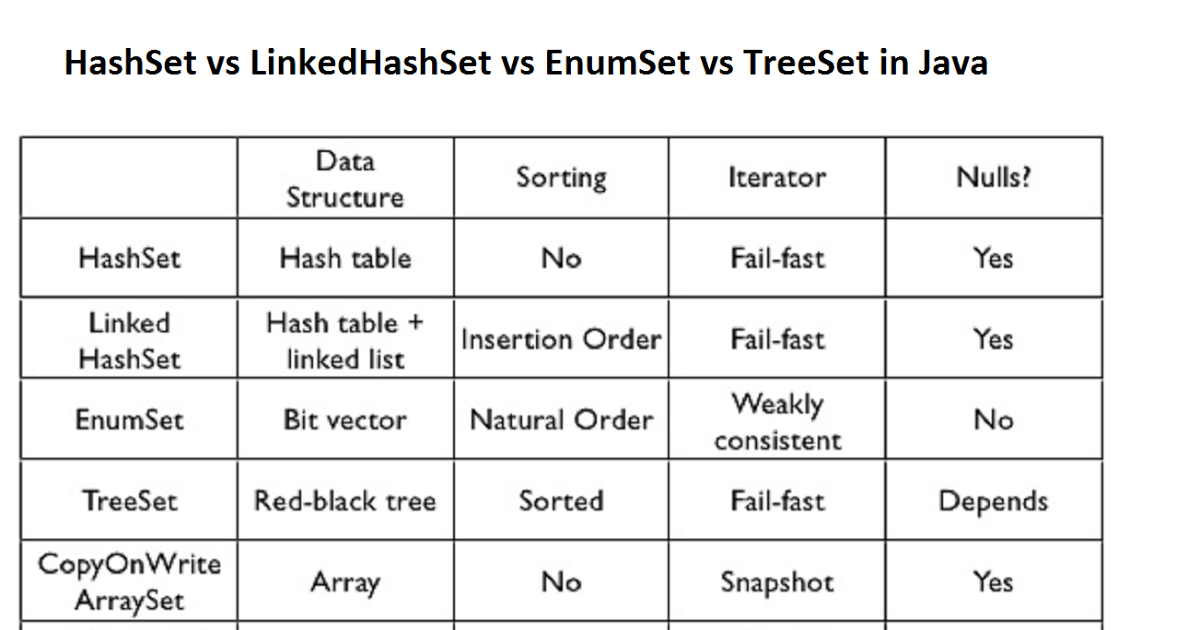
· Set no duplicates allowed.
·
· HashSet : fast. insert order not guaranteed
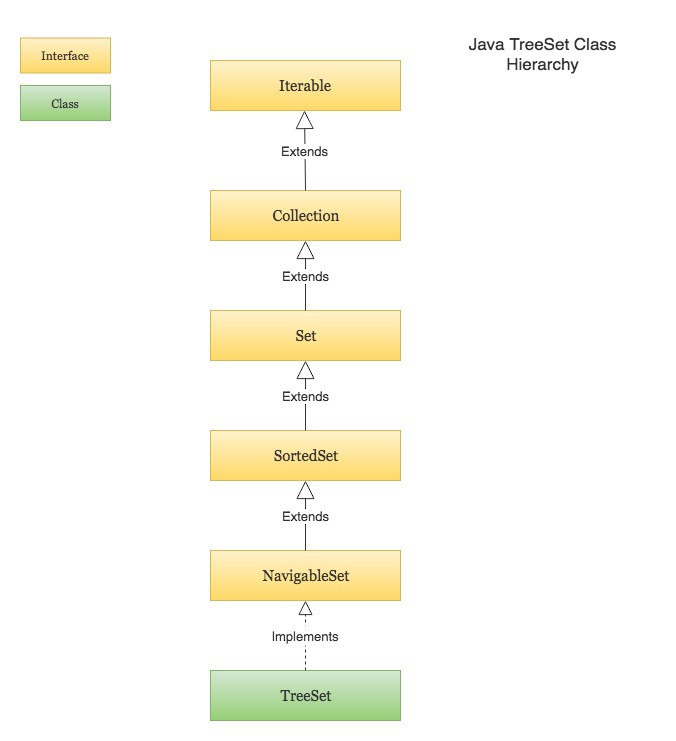
· TreeSet : sorted set
· LinkedHashSet : insertion order
·
· You cannot modify immutable object within iterator
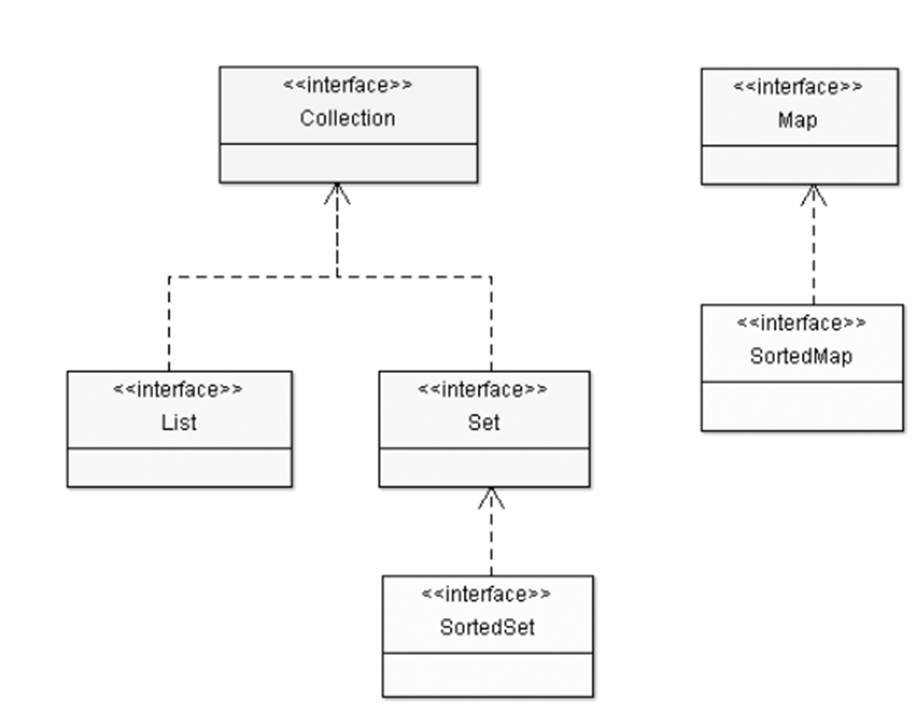
· List<E>: models a resizable linear array, which allows indexed access. List can contain duplicate elements. Frequently-used implementations of List includeArrayList, LinkedList, Vector and Stack.
· Set<E>: models a mathematical set, where no duplicate elements are allowed. Frequently-used implementations of Set are HashSet and LinkedHashSet. The sub-interface SortedSet<E> models an ordered and sorted set of elements, implemented by TreeSet.
· Queue<E>: models queues such as First-in-First-out (FIFO) queue and priority queue.
· Stack<E> is a last-in-first-out queue (LIFO) of elements. Stack extends Vector, which is a synchronized resizable array, with five additional methods:
E push(E element) // pushes the specified element onto the top of the stack
E pop() // removes and returns the element at the top of the stack
E peek() // returns the element at the top of stack without removing
boolean empty() // tests if this stack is empty
int search(Object obj) // returns the distance of the specified object from the top
// of stack (distance of 1 for TOS), or -1 if not found
· LinkedList<E> is a double-linked list implementation of the List<E> interface, which is efficient for insertion and deletion of elements, in the expense of more complex structure.
· LinkedList<E> also implements Queue<E> and Deque<E> interfaces, and can be processed from both ends of the queue. It can serve as FIFO or LIFO queue.
List to Array
|
public class TestToArray { public static void main(String[] args) { List<String> lst = new ArrayList<String>(); lst.add("alpha"); lst.add("beta"); lst.add("charlie");
// Use the Object[] version Object[] strArray1 = lst.toArray(); System.out.println(Arrays.toString(strArray1)); // [alpha, beta, charlie]
// Use the generic type verion - //Need to specify the type in the argument String[] strArray2 = lst.toArray(new String[0]); strArray2[0] = "delta"; // modify the returned array System.out.println(Arrays.toString(strArray2)); // [delta, beta, charlie] System.out.println(lst); // [alpha, beta, charlie] // - no change in the original list } }
|
Array as List
|
public class TestArrayAsList { public static void main(String[] args) { String[] strs = {"alpha", "beta", "charlie"}; System.out.println(Arrays.toString(strs)); // [alpha, beta, charlie]
List<String> lst = Arrays.asList(strs); System.out.println(lst); // [alpha, beta, charlie]
// Changes in array or list write thru strs[0] += "88"; lst.set(2, lst.get(2) + "99"); System.out.println(Arrays.toString(strs)); // [alpha88, beta, charlie99] System.out.println(lst); // [alpha88, beta, charlie99]
// Initialize a list using an array List<Integer> lstInt = Arrays.asList(22, 44, 11, 33); System.out.println(lstInt); // [22, 44, 11, 33] } }
|
· In order to sort a Collection or an array (using the Collections.sort() or Arrays.sort() methods), an ordering specification is needed.
· Some collections, in particular, SortedSet (TreeSet) and SortMap (TreeMap), are ordered. That is, the objects are stored according to a specified order.
// Sort and search an "array" of Strings
String[] array = {"Hello", "hello", "Hi", "HI"};
// Use the Comparable defined in the String class
Arrays.sort(array);
System.out.println(Arrays.toString(array)); // [HI, Hello, Hi, hello]
List<Integer> lst = new ArrayList<Integer>();
lst.add(22); // auto-box
lst.add(11);
lst.add(44);
lst.add(33);
Collections.sort(lst); // Use the Comparable of Integer class
System.out.println(lst); // [11, 22, 33, 44]
ArrayList
·
· If you always add to the end, then each element will be added to the end and stay that way until you change it.
· If you always insert at the start, then each element will appear in the reverse order you added them.
· If you insert them in the middle, the order will be something else.
ConcurrentHashMap allows multiple readers to read concurrently
without any blocking.
This is achieved by partitioning
Map into different parts based on concurrency level and locking only a portion
of Map during updates. Default concurrency level is 16, and accordingly Map is
divided into 16 part and each part is governed with a different lock. This
means, 16 thread can operate on Map simultaneously until they are operating on
different part of Map. This makes ConcurrentHashMap high performance
despite keeping thread-safety intact. Though,
it comes with a caveat. Since update operations like put(), remove(), putAll() or clear() is not synchronized, concurrent retrieval may not
reflect most recent change on Map.
synchronized(map){
if (map.get(key) == null){
return map.put(key, value);
} else{
return map.get(key);
}
}
Though this code will work fine in HashMap and Hashtable, This won't work in ConcurrentHashMap; because, during put operation whole map is not locked, and while one thread is putting value, other thread's get() call can still return null which result in one thread overriding value inserted by other thread.
ConcurrentHashMap provides putIfAbsent(key,
value) to solve this issue.
1. ConcurrentHashMap allows concurrent read and thread-safe update operation.
2. During the update operation, ConcurrentHashMap only locks a portion of Map instead of whole Map.
3. The concurrent update is achieved by internally dividing Map into the small portion which is defined by concurrency level.
5. All operations of ConcurrentHashMap are thread-safe.
6. Since ConcurrentHashMap implementation doesn't lock whole Map, there is chance of read overlapping with update operations like put() and remove().
8. ConcurrentHashMap doesn't allow null as key or value.
9. You can use ConcurrentHashMap in place of Hashtable but with caution as CHM doesn't lock whole Map.
10. During putAll() and clear() operations, the concurrent read may only reflect insertion or deletion of some entries.
Difference between CopyOnWriteArrayList and ArrayList in
Java.
1) First
and foremost difference between CopyOnWriteArrayList and
ArrayList in Java is that CopyOnWriteArrayList is a thread-safe
collection while
ArrayList is not thread-safe
2) Iterator
of ArrayList is fail-fast and
throw ConcurrentModificationException once
detect any modification in List once iteration begins but Iterator of CopyOnWriteArrayList is
fail-safe and doesn't throw ConcurrentModificationException.
3) Iterator of CopyOnWriteArrayList doesn't
support remove operation while Iterator of ArrayList supports remove() operation.
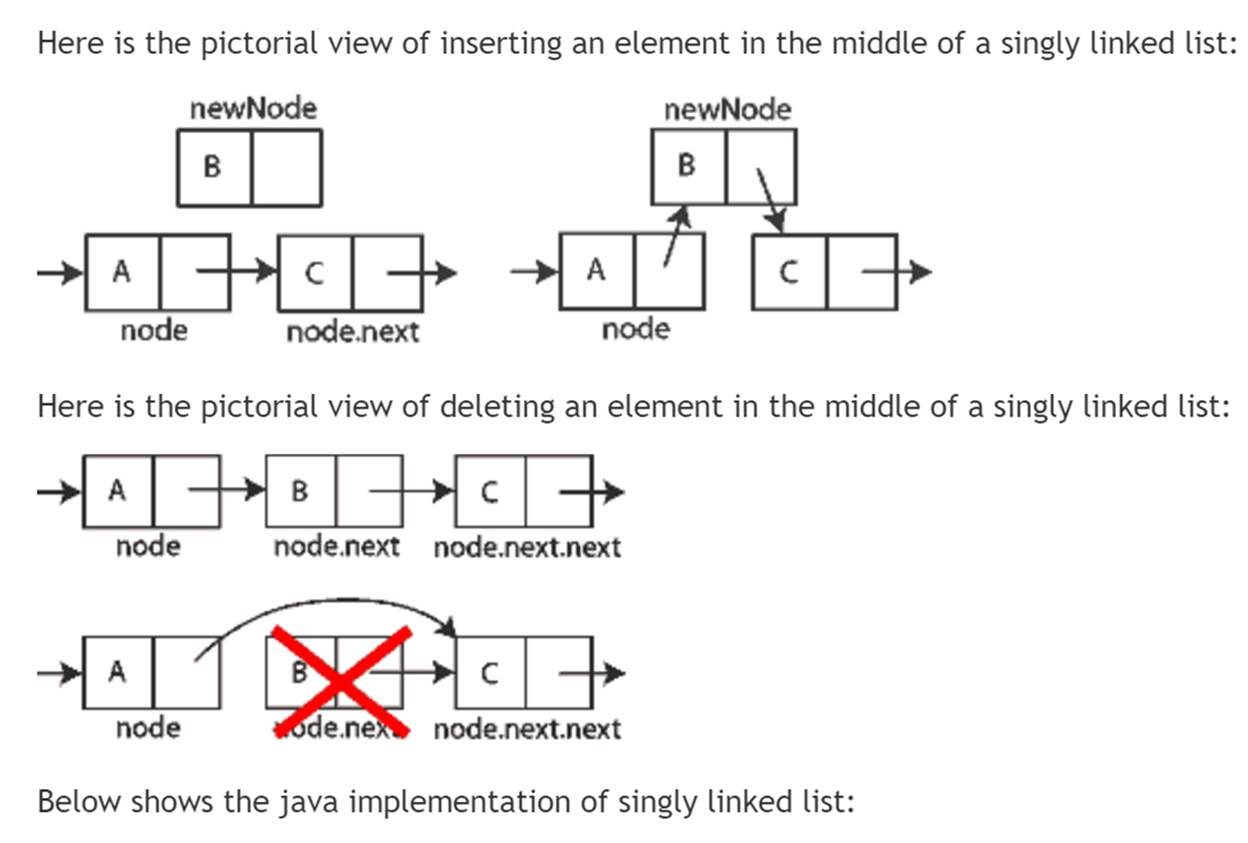
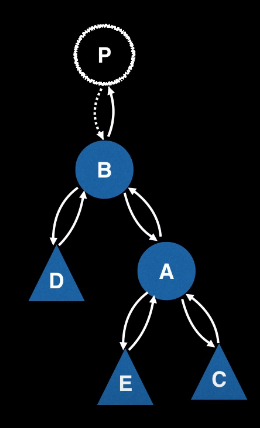
Singly linked list implementation
 |
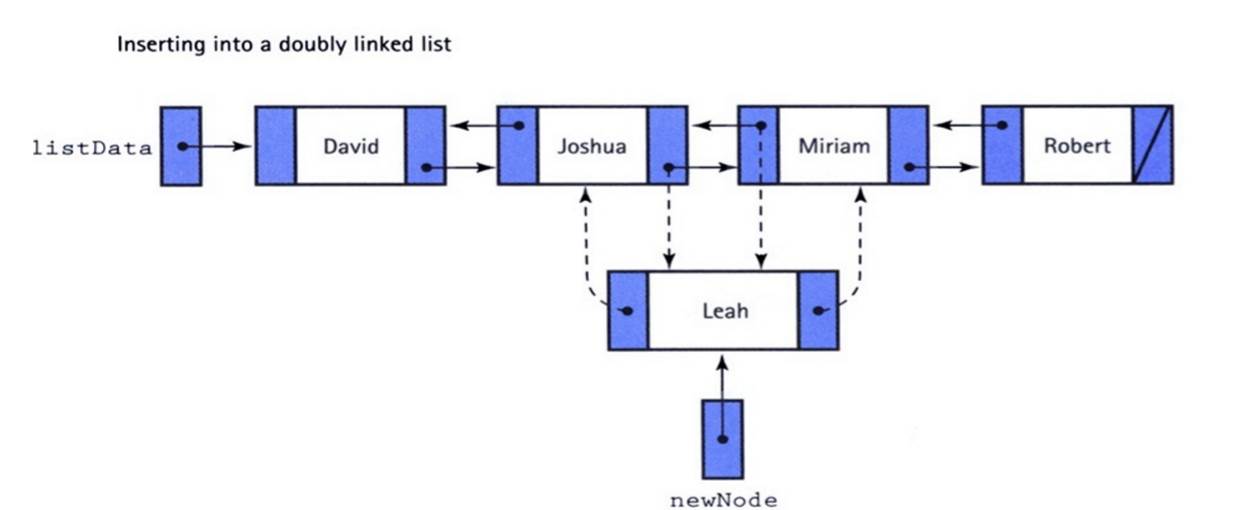 |
SingleLinkedList
|
linkedList.insertFirst(11); linkedList.insertFirst(21); linkedList.insertFirst(59); linkedList.insertFirst(14); |
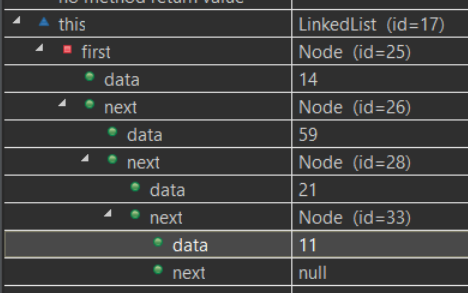 |
linkedList.deleteFirst(); will delete top one 14
it is almost like STACK type
LIFO
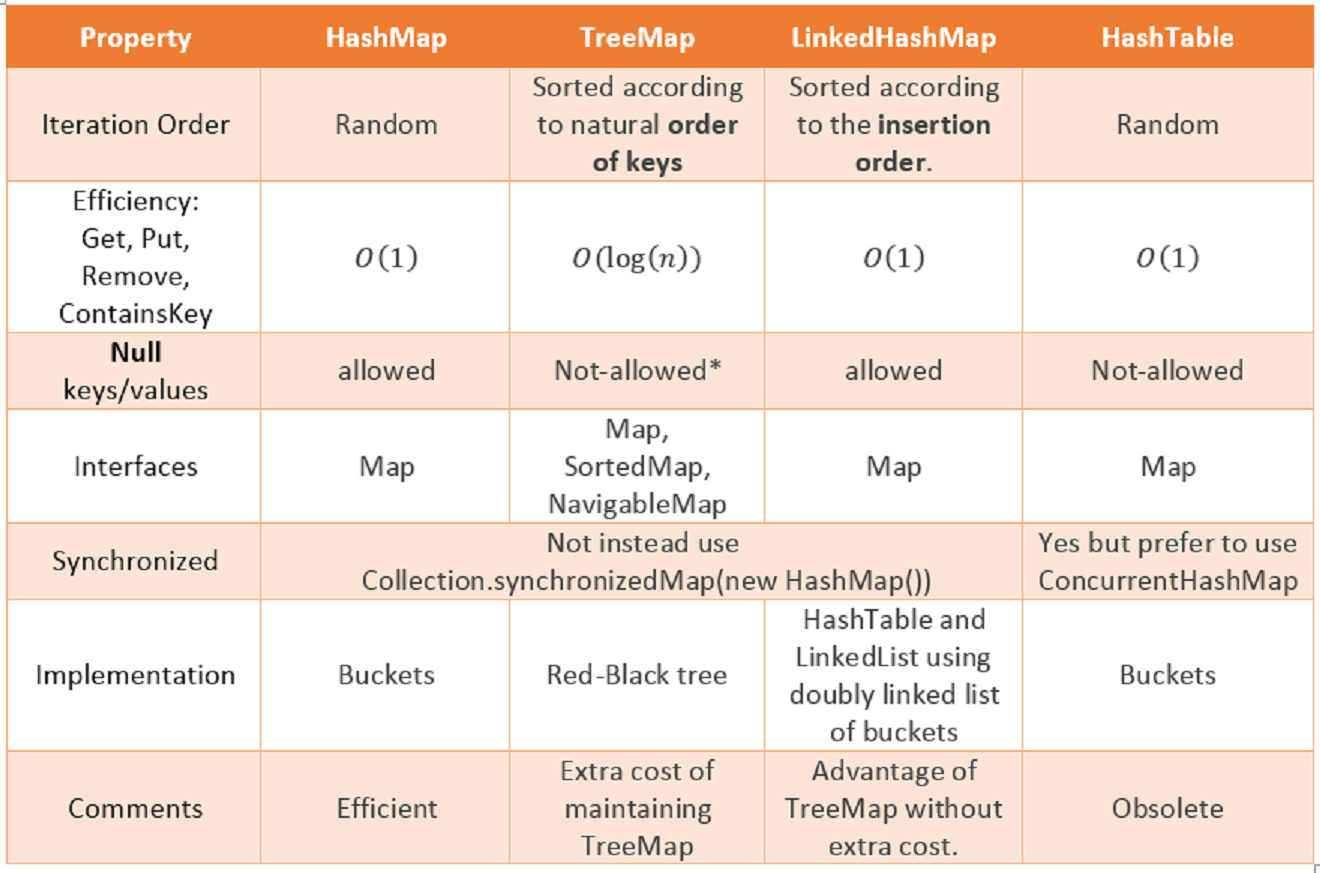
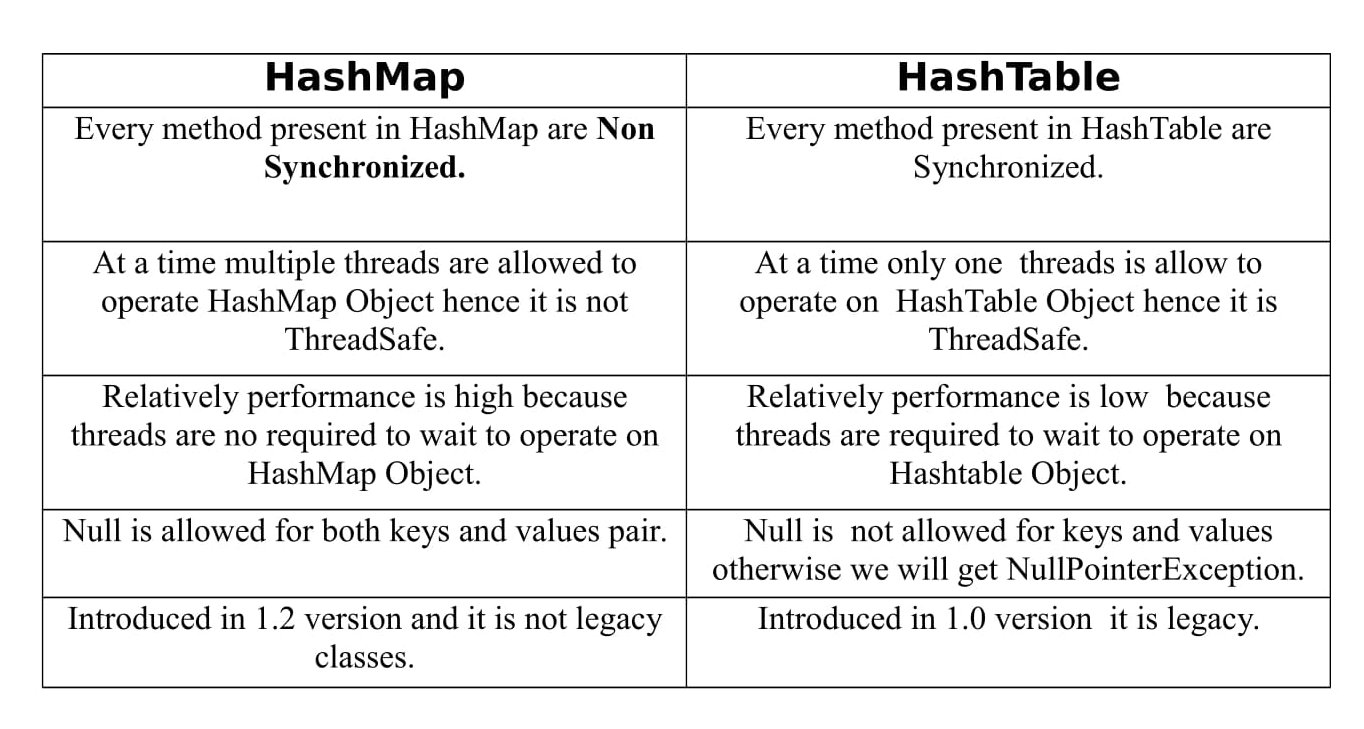
1) HashTable
All methods are thread safe
Synchronized keywords on each public method (put, get, remove)
2) HashMap
Not thread safe
No insertion order
Good for load once and then read many times from many threads.
In java8, it uses balanced tree method
3) LinkedHashMap
Insertion order
Maintains doubly linked list
4) TreeMap
SortedMap and NavigableMap interfaces
Iteration is guaranteed in “natural sorted” order of keys
Should use either Comparable interface or explicit Comparator in the constructor
Red-black tree
Approximate key
5) IdentityHashMap
Uses identity to store and retrieve key values
Uses reference equality; checking r1 == r2 rather than r1.equals(r2)
Used in serialization / deep copying
Or your key is “Class” object
No Entry / Node created
Smaller than HashMap
6) EnumMap
EnumMap <K extends Enum <K>, V>
Iterator does not fail-fast. It will not encounter ConcurrentModificationException
During iteration you can insert or delete an item.
Null keys not permitted
Not synchronized
7) WeakHashMap
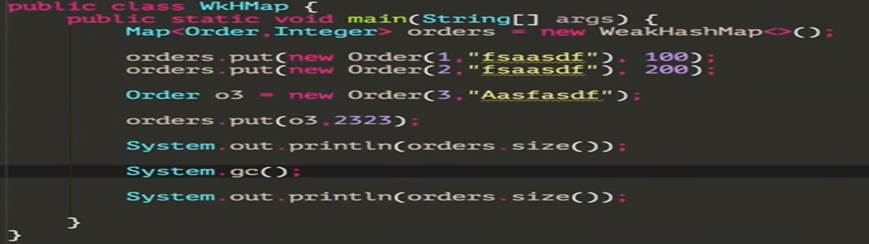 |
Elements can be reclaimed by GC if there are no other strong reference to the object of the key (not for value).
ð 3, 1
8) Collections.SynchronizedMap (aMap)
Similar to HashTable
Decorator pattern
9) Concurrent.ConcurrentHashMap
16 segments.
Operations not atomic
No nulls
Retrieval operations do not wait or block. Reads can happen fast.
Write operation lock at segment level not whole table.
Iterations do not throw concurrent modification exception within same thread.
Change to Atomic to get threadsafe
10) Concurrent.ConcurrentHashMap
A Scalable concurrent ConcurrentNavigableMap / SortedMap implementation
Guarantees average O (log (n)) performance on a wide variety of operations
But ConcurrentHashMap does not gurantee.
Arraylist
Default capacity is 10 entries
40k only for 10000
StringBuffer
Default capacity is 10 entries
24k
StringBuffer doubling its size after exceeding default capacity 16.
Eclipse Memory Analyser Tool (MAT)
Don’t create a collection until you have something to put into it
|
|
|
DoubleLinkedList
https://github.com/Vishnu24/Collection_Revised/wiki/ConcurrentHashMap
- The underlined data structure for ConcurrentHashMap is Hashtable.
- ConcurrentHashMap class is thread-safe i.e. multiple thread can operate on a single object without any complications.
- At a time any number of threads are applicable for read operation without locking the ConcurrentHashMap object which is not there in HashMap.
- In ConcurrentHashMap, the Object is divided into number of segments according to the concurrency level.
- Default concurrency-level of ConcurrentHashMap is 16.
- In ConcurrentHashMap, at a time any number of threads can perform retrieval operation but for updation in object, thread must lock the particular segment in which thread want to operate.This type of locking mechanism is known as Segment locking or bucket locking.Hence at a time 16 updation operations can be performed by threads.
- null insertion is not possible in ConcurrentHashMap as key or value.
Threadsafe queues
The BlockingQueues are ArrayBlockingQueue, DelayQueue, LinkedBlockingDeque, LinkedBlockingQueue, PriorityBlockingQueue, and SynchronousQueue.
LinkedList
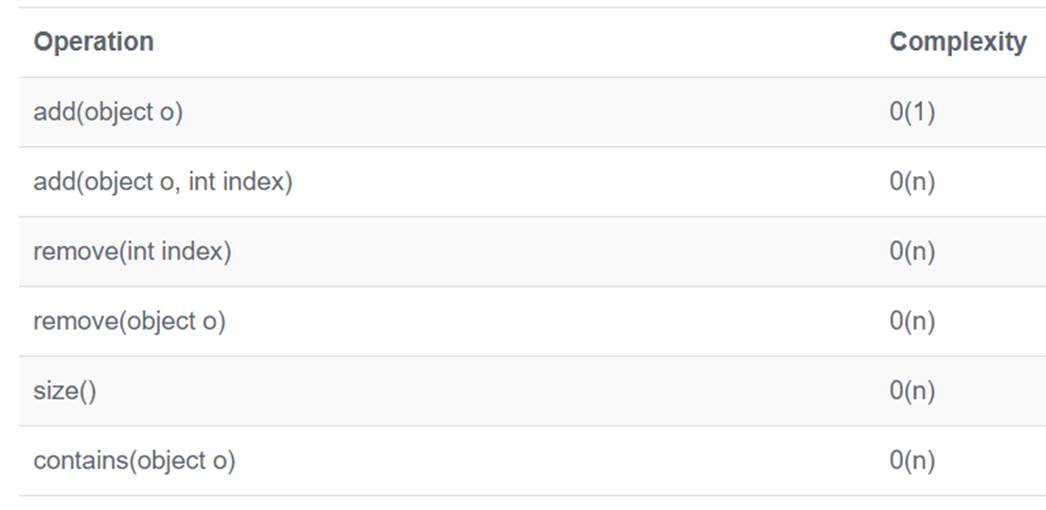
|
|
|
|
|


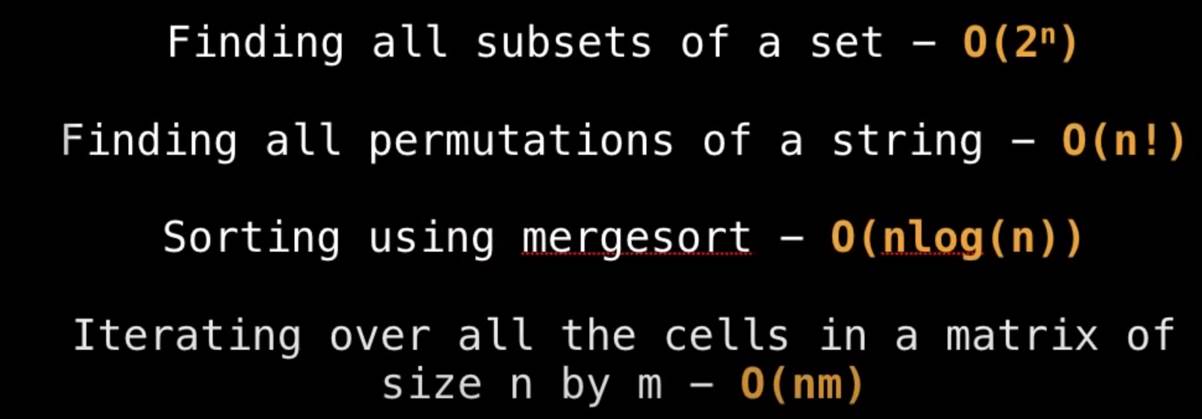

LinkedBlockingQueue
BlockingQueue methods come in four forms, with different ways of handling operations that cannot be satisfied immediately, but may be satisfied at some point in the future: one throws an exception, the second returns a special value (either null or false, depending on the operation), the third blocks the current thread indefinitely until the operation can succeed, and the fourth blocks for only a given maximum time limit before giving up. These methods are summarized in the following table:
|
Throws exception |
Special value |
Blocks |
Times out |
|
|
Insert |
||||
|
Remove |
||||
|
Examine |
not applicable |
not applicable |
A BlockingQueue does not accept null elements. Implementations throw NullPointerException on attempts to add, put or offer a null. A null is used as a sentinel value to indicate failure of poll operations.
A BlockingQueue may be capacity bounded. At any given time it may have a remainingCapacity beyond which no additional elements can be put without blocking. A BlockingQueue without any intrinsic capacity constraints always reports a remaining capacity of Integer.MAX_VALUE.
BlockingQueue implementations are designed to be used primarily for producer-consumer queues, but additionally support the Collection interface. So, for example, it is possible to remove an arbitrary element from a queue using remove(x). However, such operations are in general not performed very efficiently, and are intended for only occasional use, such as when a queued message is cancelled.
BlockingQueue implementations are thread-safe. All queuing methods achieve their effects atomically using internal locks or other forms of concurrency control. However, the bulk Collection operations addAll, containsAll, retainAll and removeAll are not necessarily performed atomically unless specified otherwise in an implementation. So it is possible, for example, for addAll(c) to fail (throwing an exception) after adding only some of the elements in c.
A BlockingQueue does not intrinsically support any kind of "close" or "shutdown" operation to indicate that no more items will be added. The needs and usage of such features tend to be implementation-dependent. For example, a common tactic is for producers to insert special end-of-stream or poison objects, that are interpreted accordingly when taken by consumers.
Usage example, based on a typical producer-consumer scenario. Note that a BlockingQueue can safely be used with multiple producers and multiple consumers.
class Producer implements Runnable {
private final BlockingQueue queue;
Producer(BlockingQueue q) { queue = q; }
public void run() {
try {
while (true) { queue.put(produce()); }
} catch (InterruptedException ex) { ... handle ...}
}
Object produce() { ... }
}
class Consumer implements Runnable {
private final BlockingQueue queue;
Consumer(BlockingQueue q) { queue = q; }
public void run() {
try {
while (true) { consume(queue.take()); }
} catch (InterruptedException ex) { ... handle ...}
}
void consume(Object x) { ... }
}
class Setup {
void main() {
BlockingQueue q = new SomeQueueImplementation();
Producer p = new Producer(q);
Consumer c1 = new Consumer(q);
Consumer c2 = new Consumer(q);
new Thread(p).start();
new Thread(c1).start();
new Thread(c2).start();
}
}
https://octoperf.com/blog/2018/03/19/java-linkedlist/
The Java LinkedList has the following properties:
- Can contain duplicate elements (i.e. elements which are equals),
- Maintains the order of insertion,
- is not synchronized (thus not thread-safe),
- Random access (through an integer index) are slow (0(n/2) on average),
- Element removal is fast because elements are stored in nodes which can be removed quickly (change links from preceding and next nodes),
- Element insertion is efficient because only a new node must be allocated (no array resize like with LinkedList).